[文章学习] 手把手教你(x)我(√)构建解释器
0x00 前言
链接:https://lotabout.me/2015/write-a-C-interpreter-0/
copy的代码在这里(看完语法分析后反而不想重写了,所以就删掉然后copy了一份)
首先,高考结束啦!(^o^)ノ
在看csapp第八章之前,打算先把之前收藏的文章跟着学一遍。一直看书太无聊了,csapp第七章大概随便就翻了翻,程序员的自我修养也没看完,感觉记忆不深,跟没学一样,所以换换脑子。
不过有一说一,这个教程做的很不错了,所以我大概也只是抄抄|ω・´)
本文的目的是让我这个啥也不懂的小白,也能理解编译器(x)解释器(√)的构成。所以我不了解的专业名词都会查阅后在下方标注,如果有错误,请大佬们指点我一下,球球了(つд⊂)
0x01 设计
首先,我们写的是个解释器而不是编译器,因为解释器需要我们实现自己的虚拟机与指令集,能让我们更好的学习。(゚3゚)
解释器:不产生目标代码,直接执行
编译器:将源代码转换成目标代码然后执行
构建过程:
- 构建虚拟机以及指令集
- 构建词法分析器,用于将字符串转化成内部的表示结构。
- 构建语法分析器,将词法分析得到的标记流(token)生成一棵语法树。
我们的编译器主要包括 4 个函数:
next()用于词法分析,获取下一个标记,它将自动忽略空白字符。program()语法分析的入口,分析整个 C 语言程序。expression(level)用于解析一个表达式。eval()虚拟机的入口,用于解释目标代码。
0x02 虚拟机
计算机内部工作原理
计算机中有三个基本部件需要我们关注:CPU、寄存器和内存。代码以二进制的形式保存在内存中;CPU从中一条一条地加载指令执行;程序运行的状态保存在寄存器中。
内存
进程的内存会被分成几个段
- 代码段(text)用于存放代码
- 数据段(data)用于存放初始化了的数据
- 未初始化数据段(bss)用于存放未初始化的数据
- 栈(stack)用于处理函数调用的相关数据
- 堆(heap)用于为程序动态分配内存
1 | +------------------+ |
寄存器
我们的虚拟机只使用4个寄存器
PC程序计数器,存放一个内存地址,该地址存放下一条要执行的计算机指令。SP指针寄存器,永远指向当前栈顶。BP基址指针,指向栈的某些位置,在调用函数时会用到它。AX通用寄存器,它用于存放一条指令执行后的结果。
0x03 词法分析器
词法分析器用于对源码字符串做预处理,以减少语法分析器的复杂程度。词法分析器以源码字符串为输入,输出为标记流(token stream)。
每个标记通常包括:(token, token value)即标记本身和标记的值。例如,源码中若包含一个数字'998',词法分析器将输出(Number, 998),即(数字,998)。
1 | //例如: |
我们可以理解为,直接从源代码编译成汇编代码是比较困难的,因为输入的字符串比较难处理。所以我们先编写一个词法分析器将字符串转换成标记流,然后再由编译器把标记流转换成汇编。
1 | +-------+ +--------+ |
词法分析器的实现
我们不会一次性把所有源码转换成token stream,因为保存所有的token stream是没有意义且浪费空间的,并且字符串与代码的上下文是有关系的。
词法分析器会把扫描到的标识符(变量名的标识)全部保存到一张表中,遇到新的标识符就去查这张表,如果标识符已经存在,就返回它的唯一标识。
1 | struct identifier { |
然后代码的主要就是通过分析来确定标记。对于关键字if,while,return等等,我们把它们加入符号表
- 词法分析器的作用是对源码字符串进行预处理,作用是减小语法分析器的复杂程度。
- 词法分析器本身可以认为是一个编译器,输入是源码,输出是标记流。
lookahead(k)的概念,即向前看k个字符或标记。- 词法分析是怎么处理标识符与符号表的。
lookahead:如果有多个标记是以同样的字符开头的,凭借当前的字符我们无法确定具体解释成哪一个标记,所以我们只能向前查看字符判断解释的标记。
0x04 语法分析器
终结符与非终结符
1 | <expr> ::= <expr> + <term> |
用尖括号<>括起来的就是非终结符,因为它们可以用::=右边的式子代替。|的意思是或,比如说:expr中那三个式子都可以替换expr。
没出现在::=左边的就是终结符,终结符一般对应词法分析器输出的标记。
递归下降
编写语法分析器有两种方法,一种是从起始非终结符开始,不断把非终结符分解,直到匹配输入的终结符;另一种是把终结符不断合并,直到合成非终结符。
我们用的是第二种,也就是递归下降。
它的过程是:
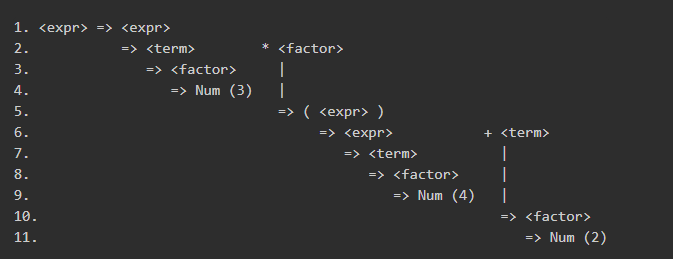
再后面就是将语句等编译成汇编代码了
语句
语句:语句就是表达式加上;。
我们的编译器中识别6种语句:
if (...) <statement> [else <statement>]while (...) <statement>{ <statement> }return xxx;<empty statement>;expression;(expression end with semicolon)
1 | if (...) <statement> [else <statement>] |
1 | if (token == If) { |
只有if,while,return生成汇编代码。其余不生成。
match函数用于比较token是否正确,如果不正确就会报错退出。
解析表达式主要是实现运算符优先级这里麻烦一些。
0x05 总结
回答一下我开这个坑的疑问:编写编译器(不,这是解释器)的过程大概是怎样的。
答:
- 首先我们要写一个虚拟机,里面划分堆栈段。然后写出基本的寄存器。
- 再然后要制作我们自己的指令集。我们可以把代码转换成汇编,然后存放在虚拟机的text段。
- 然后就是写词法分析器,它会把源码修改成标记,为了方便语法分析器。
- 到了语法分析器,
3*4可能就已经被修改成了num1 Mul num2。 - 最后需要把这些变成汇编语言就可以了。
代码就先不写了,因为目前用不到。可能以后深入的话,学点更难的。
另外我是懒狗,如果想要学好点的话,最好把代码抄一遍()