PA0-世界诞生的前夜 https://nju-projectn.github.io/ics-pa-gitbook/ics2019/
本文仅仅是对笔者自己知识遗漏的一个补充,可以辅助本文学习PA,但请不要只看本文。
有些代码参考了别的师傅,若文中有些代码运行失败,请优先查看github上的源码,然后麻烦联系我修改文章以免误导别人。万分感谢。
环境配置 我安装了一个debian10,这个怎么装就不说了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 echo "deb http://mirrors.tuna.tsinghua.edu.cn/debian/ stable main" > /etc/apt/sources.listapt-get update apt-get install build-essential apt-get install man apt-get install net-tools apt-get install vim apt-get install gdb apt-get install git apt-get install libreadline-dev apt-get install libsdl2-dev apt-get install libc6-dev-i386 apt-get install qemu-system git clone -b 2019 https://github.com/NJU-ProjectN/ics-pa.git ics2019 git config --global user.name "kazamayc" git config --global user.email "kazamayc@gmail.com" git config --global core.editor vim git config --global color.ui true bash init.sh source ~/.bashrcmake
tmux使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 tmux 创建新会话 exit和ctrl+d 关闭会话 ctrl+b d 退出当前会话,但是不关闭,仍在后台运行 ctrl+b s 列出所有会话,这里的切换上下可以用vim语法(太贴心了) ctrl+b $ 重命名当前会话 ctrl+b % 划分左右两个会话 ctrl+b " 划分上下两个会话 ctrl+b ; 切换到上一个会话 ctrl+b o 切换到下一个会话 ctrl+b { 当前会话与上一个会话交换位置 ctrl+b } 当前会话和下一个会话交换位置 ctrl+b ctrl+o 所有会话向后移动一个位置,最后一个会话变成第一个会话 ctrl+b ! 把当前会话拆分成一个 ctrl+b z 把当前会话全屏显示,再用一次会恢复大小 ctrl+b q 显示会话编号 ctrl+b c 创建一个新会话 ctrl+b p 切换到上一个会话 ctrl+b n 切换到下一个会话 ctrl+b <num> 切换到指定编号的窗口 ctrl+b w 从列表中选择会话 ctrl+b , 会话重命名
PA1-开天辟地的篇章
task PA1.1: 实现单步执行, 打印寄存器状态, 扫描内存
task PA1.2: 实现算术表达式求值
task PA1.3: 实现所有要求, 提交完整的实验报告
1.)如何玩超级马里奥
在nexus-am/apps/litenes/目录下执行make rom生成ROM文件,然后执行make run mainargs=mario就可以运行。
其他游戏查看nexus-am/apps/litenes/src/roms/rom的内容,然后对mainargs进行修改即可。
1 2 3 4 5 6 7 操作方式: * T — SELECT * Y — START * G — A键 * H — B键 * W/S/A/D — UP/DOWN/LEFT/RIGHT
2.)一台简单的计算机 计算机运行的程序是由代码和数据组成的,而计算机是怎么运行程序的呢?
结构上, 一台简单的计算机要有存储程序的存储器 ,有用于暂存数据加快运算的寄存器 ,有用于计算的运算器 ,有永远指向当前执行指令的程序计数器PC
1 2 3 4 5 while (1 ) { 从PC指示的存储器位置取出指令; 执行指令; 更新PC; }
3.)框架代码初探 1 2 3 4 5 6 7 8 ics2019 ├── init.sh # 初始化脚本 ├── Makefile # 用于工程打包提交 ├── nanos-lite # 微型操作系统内核 ├── navy-apps # 应用程序集 ├── nemu # NEMU ├── nexus-am # 抽象计算机 └── README.md
目前我们只需要学习NEMU,NEMU主要由四个部分构成:monitor,CPU,memory,设备。它的功能是负责模拟出一套计算机硬件,让程序可以在其上运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 nemu ├── include # 存放全局使用的头文件 │ ├── common.h # 公用的头文件 │ ├── cpu │ │ ├── decode.h # 译码相关 │ │ └── exec.h # 执行相关 │ ├── debug.h # 一些方便调试用的宏 │ ├── device # 设备相关 │ ├── macro.h # 一些方便的宏定义 │ ├── memory # 访问内存相关 │ ├── monitor │ │ ├── expr.h # 表达式求值相关 │ │ ├── log.h # 日志文件相关 │ │ ├── monitor.h │ │ └── watchpoint.h # 监视点相关 │ ├── nemu.h │ └── rtl │ ├── rtl.h # RTL基本指令 │ └── rtl-wrapper.h ├── Makefile # 指示NEMU的编译和链接 ├── Makefile.git # git版本控制相关 ├── runall.sh # 一键测试脚本 └── src # 源文件 ├── cpu │ └── cpu.c # 执行一条指令 ├── device # 设备相关 ├── isa # ISA相关的实现 │ ├── mips32 │ ├── riscv32 │ └── x86 ├── main.c # 你知道的... ├── memory │ └── memory.c # 访问内存的接口函数 └── monitor ├── cpu-exec.c # 指令执行的主循环 ├── debug # 简易调试器相关 │ ├── expr.c # 表达式求值的实现 │ ├── log.c # 日志文件相关 │ ├── ui.c # 用户界面相关 │ └── watchpoint.c # 监视点的实现 ├── diff-test └── monitor.c
4.)阅读NEMU代码 1 2 3 4 5 6 7 8 9 10 11 12 int init_monitor (int , char *[]) void ui_mainloop (int ) int main (int argc, char *argv[]) int is_batch_mode = init_monitor(argc, argv); ui_mainloop(is_batch_mode); return 0 ; }
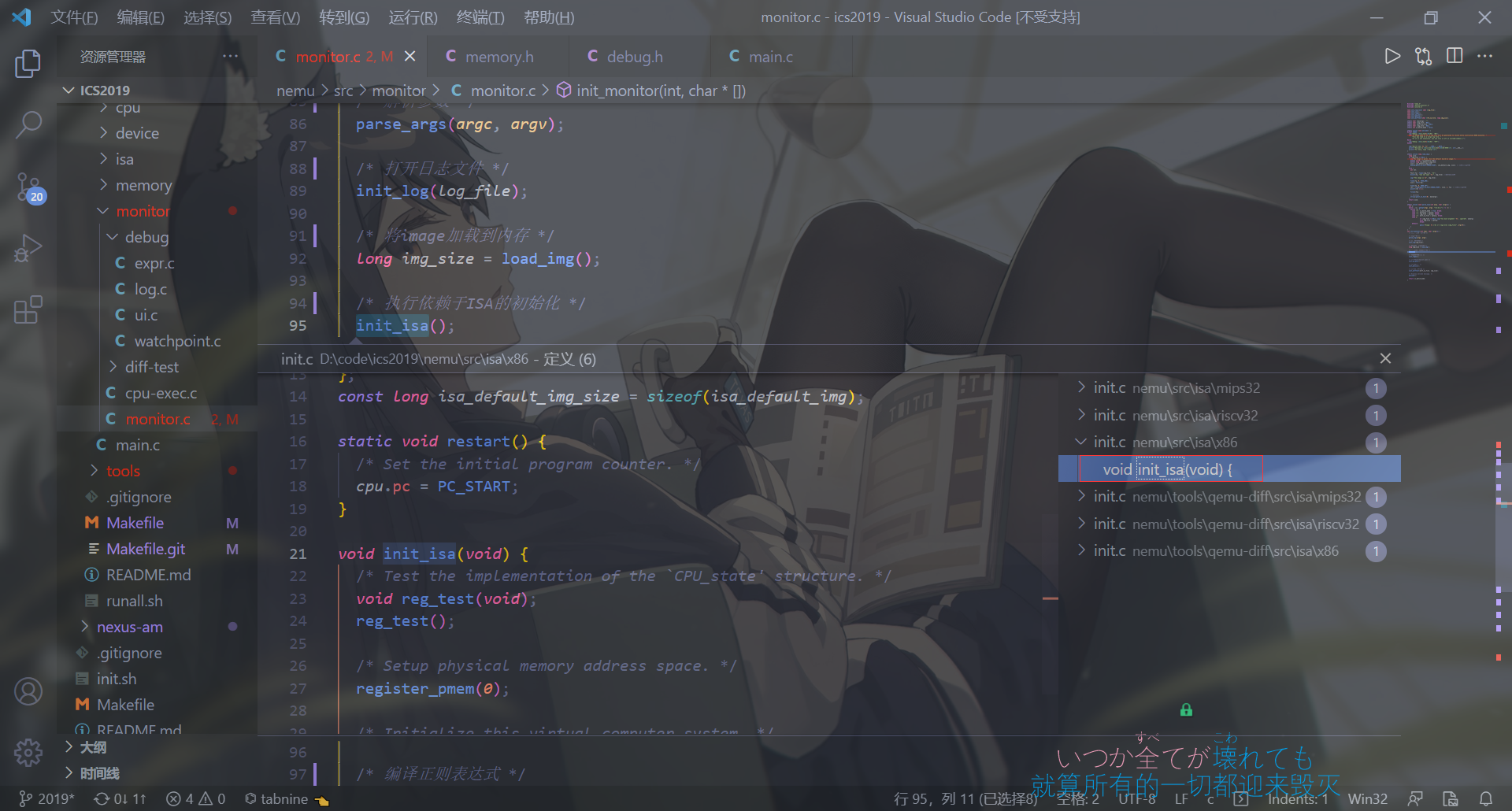
Monitor模块是为了方便地监控客户计算机的运行状态而引入的,它除了负责与GNU/Linux进行交互(例如读入客户程序)之外,还带有调试器的功能,为NEMU的调试提供了方便的途径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 int init_monitor (int argc, char *argv[]) parse_args(argc, argv); init_log(log_file); long img_size = load_img(); init_isa(); init_regex(); init_wp_pool(); init_device(); init_difftest(diff_so_file, img_size); welcome(); return is_batch_mode; }
parse_args 我们挨个解析函数,首先是解析参数。这里还用于读入镜像。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static char *mainargs = "" ;static char *log_file = NULL ;static char *diff_so_file = NULL ;static char *img_file = NULL ;static int is_batch_mode = false ;static inline void parse_args (int argc, char *argv[]) int o; while ( (o = getopt(argc, argv, "-bl:d:a:" )) != -1 ) { switch (o) { case 'b' : is_batch_mode = true ; break ; case 'a' : mainargs = optarg; break ; case 'l' : log_file = optarg; break ; case 'd' : diff_so_file = optarg; break ; case 1 : if (img_file != NULL ) Log("too much argument '%s', ignored" , optarg); else img_file = optarg; break ; default : panic("Usage: %s [-b] [-l log_file] [img_file]" , argv[0 ]); } } }
int getopt(int argc, char * const argv[ ], const char * optstring);
getopt作用: getopt用于分析参数。前两个参数就是main的参数。后面是个选项字符串:上文中的-bl:d:a:就是命令行中对应的-b -l -d -a,冒号表示这个选项后面必须带有参数,可以和选项连在一起写,也可以用空格隔开。两个冒号表示参数可选,就是可以带有参数也可以不带。
optarg指向额外参数
return value: 如果选项成功找到,返回选项字母。当所有命令行被解析,则getopt返回-1。如果存在未知的选项或缺失选项,getopt会返回?。
init_log 然后是打开log
1 2 3 4 5 6 7 8 FILE *log_fp = NULL ; void init_log (const char *log_file) if (log_file == NULL ) return ; log_fp = fopen(log_file, "w" ); Assert(log_fp, "Can not open '%s'" , log_file); }
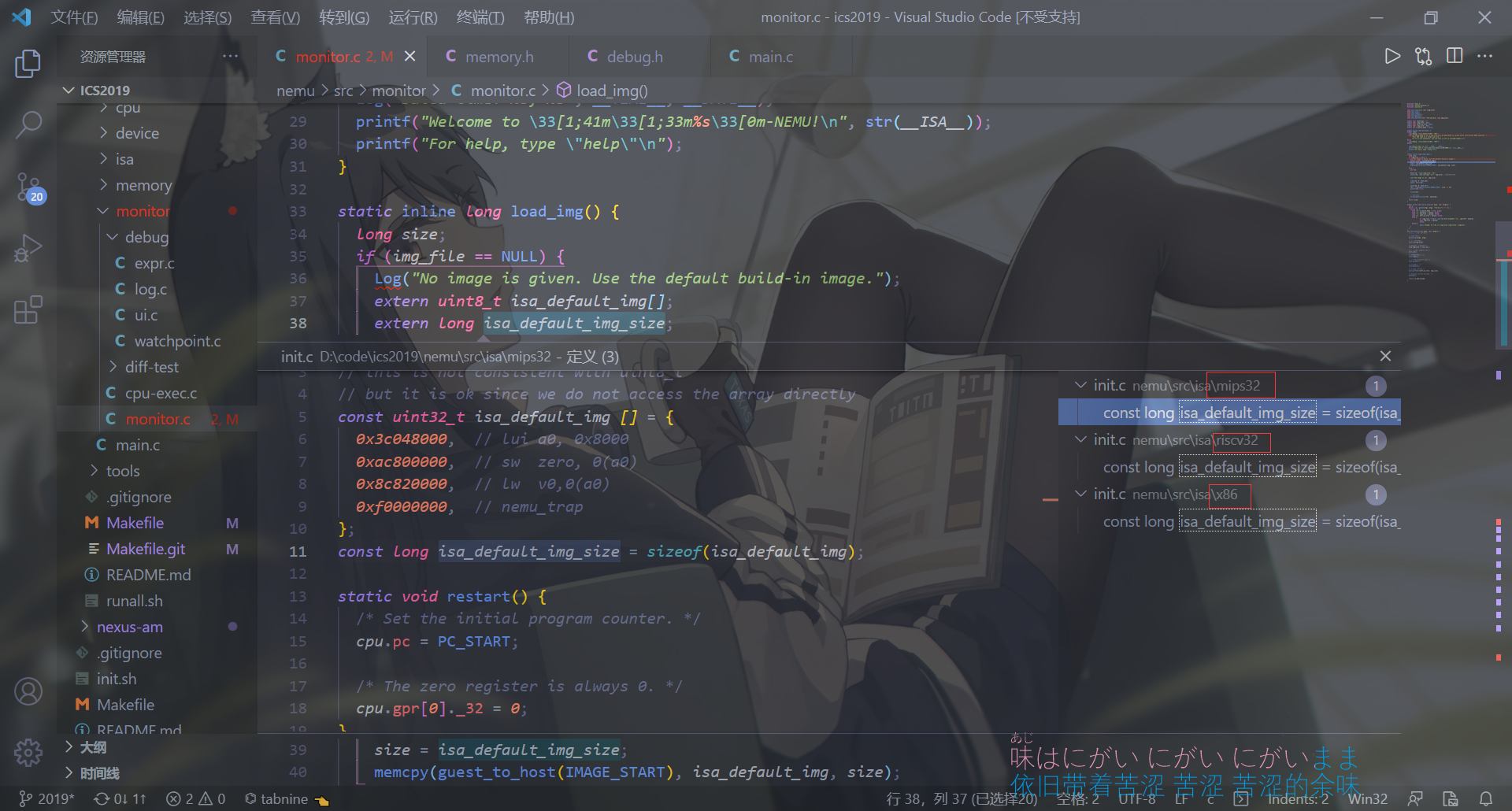
load_img 将镜像文件读取到计算机内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #define IMAGE_START 0x100000 #define guest_to_host(p) ((void *)(pmem + (unsigned)p)) static char *mainargs = "" ;static char *img_file = NULL ;static inline long load_img () long size; if (img_file == NULL ) { Log("No image is given. Use the default build-in image." ); extern uint8_t isa_default_img[]; extern long isa_default_img_size; size = isa_default_img_size; memcpy (guest_to_host(IMAGE_START), isa_default_img, size); } else { int ret; FILE *fp = fopen(img_file, "rb" ); Assert(fp, "Can not open '%s'" , img_file); Log("The image is %s" , img_file); fseek(fp, 0 , SEEK_END); size = ftell(fp); fseek(fp, 0 , SEEK_SET); ret = fread(guest_to_host(IMAGE_START), size, 1 , fp); assert(ret == 1 ); fclose(fp); strcpy (guest_to_host(0 ), mainargs); } return size; }
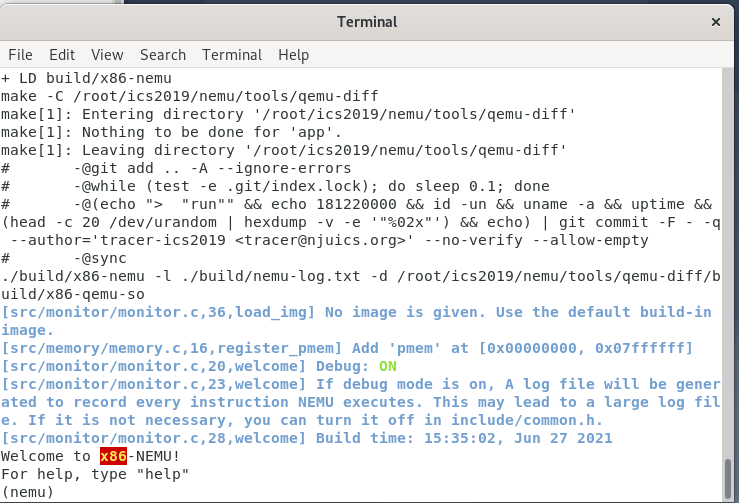
如果没有镜像文件,就会根据你选择的ISA读取内置程序。本文选择的ISA是x86,下面阅读的代码也将是x86。
简单科普一下vscode快捷键,方便大家审阅代码。
f12 转到定义alt+方向键的← 返回alt+方向键的→ 前进
1 2 3 4 5 6 7 8 9 10 11 12 const uint8_t isa_default_img [] = { 0xb8 , 0x34 , 0x12 , 0x00 , 0x00 , 0xb9 , 0x27 , 0x00 , 0x10 , 0x00 , 0x89 , 0x01 , 0x66 , 0xc7 , 0x41 , 0x04 , 0x01 , 0x00 , 0xbb , 0x02 , 0x00 , 0x00 , 0x00 , 0x66 , 0xc7 , 0x84 , 0x99 , 0x00 , 0xe0 , 0xff , 0xff , 0x01 , 0x00 , 0xb8 , 0x00 , 0x00 , 0x00 , 0x00 , 0xd6 , }; const long isa_default_img_size = sizeof (isa_default_img);
BIOS和计算机启动
内存是一种RAM,这意味着计算机在刚启动的时候,内存中的数据都是没有意义的。BIOS是一种ROM,它的内容不会因为断电而丢失。
PA中对这些细节做了简化,采用约定的方式让CPU直接从约定的内存位置开始执行。
init_isa 同样的,下一个函数初始化ISA,我们选择阅读x86代码(以下将不再提示,将会直接选择x86代码)
1 2 3 4 5 6 7 8 9 10 11 void init_isa (void ) void reg_test (void ) reg_test(); register_pmem(0 ); restart(); }
第一个作业就是让我们实现寄存器结构体,reg_test函数会生成随机数据,对我们写的代码进行测试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 typedef struct { word PC; byte SP; byte A, X, Y; byte P; } CPU_STATE; CPU_state cpu; enum {#define reg_l(index) (cpu.gpr[check_reg_index(index)]._32) void reg_test () srand(time(0 )); uint32_t sample[8 ]; uint32_t pc_sample = rand(); cpu.pc = pc_sample; int i; for (i = R_EAX; i <= R_EDI; i ++) { sample[i] = rand(); reg_l(i) = sample[i]; assert(reg_w(i) == (sample[i] & 0xffff )); } assert(reg_b(R_AL) == (sample[R_EAX] & 0xff )); assert(reg_b(R_AH) == ((sample[R_EAX] >> 8 ) & 0xff )); assert(reg_b(R_BL) == (sample[R_EBX] & 0xff )); assert(reg_b(R_BH) == ((sample[R_EBX] >> 8 ) & 0xff )); assert(reg_b(R_CL) == (sample[R_ECX] & 0xff )); assert(reg_b(R_CH) == ((sample[R_ECX] >> 8 ) & 0xff )); assert(reg_b(R_DL) == (sample[R_EDX] & 0xff )); assert(reg_b(R_DH) == ((sample[R_EDX] >> 8 ) & 0xff )); assert(sample[R_EAX] == cpu.eax); assert(sample[R_ECX] == cpu.ecx); assert(sample[R_EDX] == cpu.edx); assert(sample[R_EBX] == cpu.ebx); assert(sample[R_ESP] == cpu.esp); assert(sample[R_EBP] == cpu.ebp); assert(sample[R_ESI] == cpu.esi); assert(sample[R_EDI] == cpu.edi); assert(pc_sample == cpu.pc); }
如果对随机不太了解,可以试一试下面的程序。
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> #include <time.h> #include <stdlib.h> int main () printf ("time: %d\n" ,time(0 )); printf ("rand1: %d\n" ,rand()); srand(1 ); printf ("rand2: %d\n" ,rand()); srand(time(0 )); printf ("rand3: %d\n" ,rand()); }
如果对enum不太了解,可以试试下面的程序
1 2 3 4 5 6 7 8 enum {#include <stdio.h> int main () printf ("%d" ,R_EAX); printf ("%d" ,R_ECX); printf ("%d" ,R_EDX); }
然后是register_pmem函数,我们用它记录了物理内存的地址(NEMU默认为128MB的物理内存)。对于一些ISA来说,物理内存并不是从0开始的,例如mips32和riscv32的物理地址均从0x80000000开始。因此我们需要记录其物理内存的起始地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static IOMap pmem_map = { .name = "pmem" , .space = pmem, .callback = NULL }; typedef struct { char *name; paddr_t low; paddr_t high; uint8_t *space; io_callback_t callback; } IOMap; #define PMEM_SIZE (128 * 1024 * 1024) void register_pmem (paddr_t base) pmem_map.low = base; pmem_map.high = base + PMEM_SIZE - 1 ; Log("Add '%s' at [0x%08x, 0x%08x]" , pmem_map.name, pmem_map.low, pmem_map.high); }
最后是restart函数,它用于初始化寄存器。设置pc指针到我们约定好的地方。
1 2 3 4 5 6 #define PC_START (0x80000000u + IMAGE_START) #define IMAGE_START 0x100000 static void restart () cpu.pc = PC_START; }
初始化后的内存布局 读入客户程序并对寄存器进行初始化后的内存的布局如下:
1 2 3 4 5 6 7 8 9 10 11 pmem: 0 0x100000 ----------------------------------------------- | | | | | guest prog | | | | ----------------------------------------------- ^ | pc
作业1 要求:我们需要完善CPU_state结构体,访问cpu.gpr[3]._16,我们将得到bx寄存器;访问cpu.gpr[1]._8[1],我们将得到ch寄存器。
1 2 3 4 5 6 7 8 9 10 11 12 13 typedef struct { union { union { uint32_t _32; uint16_t _16; uint8_t _8[2 ]; }gpr[8 ]; struct { rtlreg_t eax, ecx, edx, ebx, esp, ebp, esi, edi; }; }; vaddr_t pc; } CPU_state;
简单解释一下上文的代码(有关union请查看这篇文章 或者百度)。
1 2 3 4 5 union { uint32_t _32; uint16_t _16; uint8_t _8[2]; }
上面的代码在内存中分配了uint32_t的空间,也就是32位。加上gpr[8]后,分配32*8的空间。然后我们存放寄存器的结构体,也分配了32*8的空间,这样我们的union就对应上了。
ui_mainloop
当出现这个界面的时候,说明monitor的初始化工作已经完成,我们进入了ui_mainloop函数。
1 2 3 4 5 6 7 8 9 10 static int cmd_c (char *args) cpu_exec(-1 ); return 0 ; } void cpu_exec (uint64_t n) for (; n > 0 ; n --) { __attribute__((unused)) vaddr_t ori_pc = cpu.pc; __attribute__((unused)) vaddr_t seq_pc = exec_once(); }
然后我们输入c,程序就会执行我们之前load_img默认的客户程序。详细请查看PA文档。
补充 三个对调试有用的宏(在nemu/include/debug.h中定义):
Log()是printf()的升级版,专门用来输出调试信息,同时还会输出使用Log()所在的源文件,行号和函数,当输出的调试信息过多的时候,可以很方便地定位到代码中的相关位置;Assert()是assert()的升级版,当测试条件为假时,在assertion fail之前可以输出一些信息;panic()用于输出信息并结束程序,相当于无条件的assertion fail。
代码框架:
vaddr,paddr分别代表虚拟地址和物理地址;
存储器是个在nemu/src/memory/memory.c中定义的大数组;
PC和通用寄存器都在nemu/src/isa/$ISA/include/isa/reg.h中的结构体中定义;
加法器在PA2介绍;
TRM(图灵机)的工作方式通过cpu_exec()和exec_once()体现。
正经的ui_mainloop解析 上面那个是不正经的(逃)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void ui_mainloop (int is_batch_mode) if (is_batch_mode) { cmd_c(NULL ); return ; } for (char *str; (str = rl_gets()) != NULL ; ) { char *str_end = str + strlen (str); char *cmd = strtok(str, " " ); if (cmd == NULL ) { continue ; } char *args = cmd + strlen (cmd) + 1 ; if (args >= str_end) { args = NULL ; } #ifdef HAS_IOE extern void sdl_clear_event_queue (void ) sdl_clear_event_queue(); #endif int i; for (i = 0 ; i < NR_CMD; i ++) { if (strcmp (cmd, cmd_table[i].name) == 0 ) { if (cmd_table[i].handler(args) < 0 ) { return ; } break ; } } if (i == NR_CMD) { printf ("Unknown command '%s'\n" , cmd); } } }
执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 if (is_batch_mode) { cmd_c(NULL ); return ; } static int cmd_c (char *args) cpu_exec(-1 ); return 0 ; } void cpu_exec (uint64_t n) switch (nemu_state.state) { case NEMU_END: case NEMU_ABORT: printf ("Program execution has ended. To restart the program, exit NEMU and run again.\n" ); return ; default : nemu_state.state = NEMU_RUNNING; } for (; n > 0 ; n --) { __attribute__((unused)) vaddr_t ori_pc = cpu.pc; __attribute__((unused)) vaddr_t seq_pc = exec_once();
解析参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 for (char *str; (str = rl_gets()) != NULL ; ) { char *str_end = str + strlen (str); char *cmd = strtok(str, " " ); if (cmd == NULL ) { continue ; } char *args = cmd + strlen (cmd) + 1 ; if (args >= str_end) { args = NULL ; } #ifdef HAS_IOE extern void sdl_clear_event_queue (void ) sdl_clear_event_queue(); #endif int i; for (i = 0 ; i < NR_CMD; i ++) { if (strcmp (cmd, cmd_table[i].name) == 0 ) { if (cmd_table[i].handler(args) < 0 ) { return ; } break ; } } if (i == NR_CMD) { printf ("Unknown command '%s'\n" , cmd); } } static char * rl_gets () static char *line_read = NULL ; if (line_read) { free (line_read); line_read = NULL ; } line_read = readline("(nemu) " ); if (line_read && *line_read) { add_history(line_read); } return line_read; } static struct { char *name; char *description; int (*handler) (char *); } cmd_table [] = { { "help" , "Display informations about all supported commands" , cmd_help }, { "c" , "Continue the execution of the program" , cmd_c }, { "q" , "Exit NEMU" , cmd_q }, };
cmd_help 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static int cmd_help (char *args) char *arg = strtok(NULL , " " ); int i; if (arg == NULL ) { for (i = 0 ; i < NR_CMD; i ++) { printf ("%s - %s\n" , cmd_table[i].name, cmd_table[i].description); } } else { for (i = 0 ; i < NR_CMD; i ++) { if (strcmp (arg, cmd_table[i].name) == 0 ) { printf ("%s - %s\n" , cmd_table[i].name, cmd_table[i].description); return 0 ; } } printf ("Unknown command '%s'\n" , arg); } return 0 ; }
至于else后面的代码,用实现来看会更加直观一点
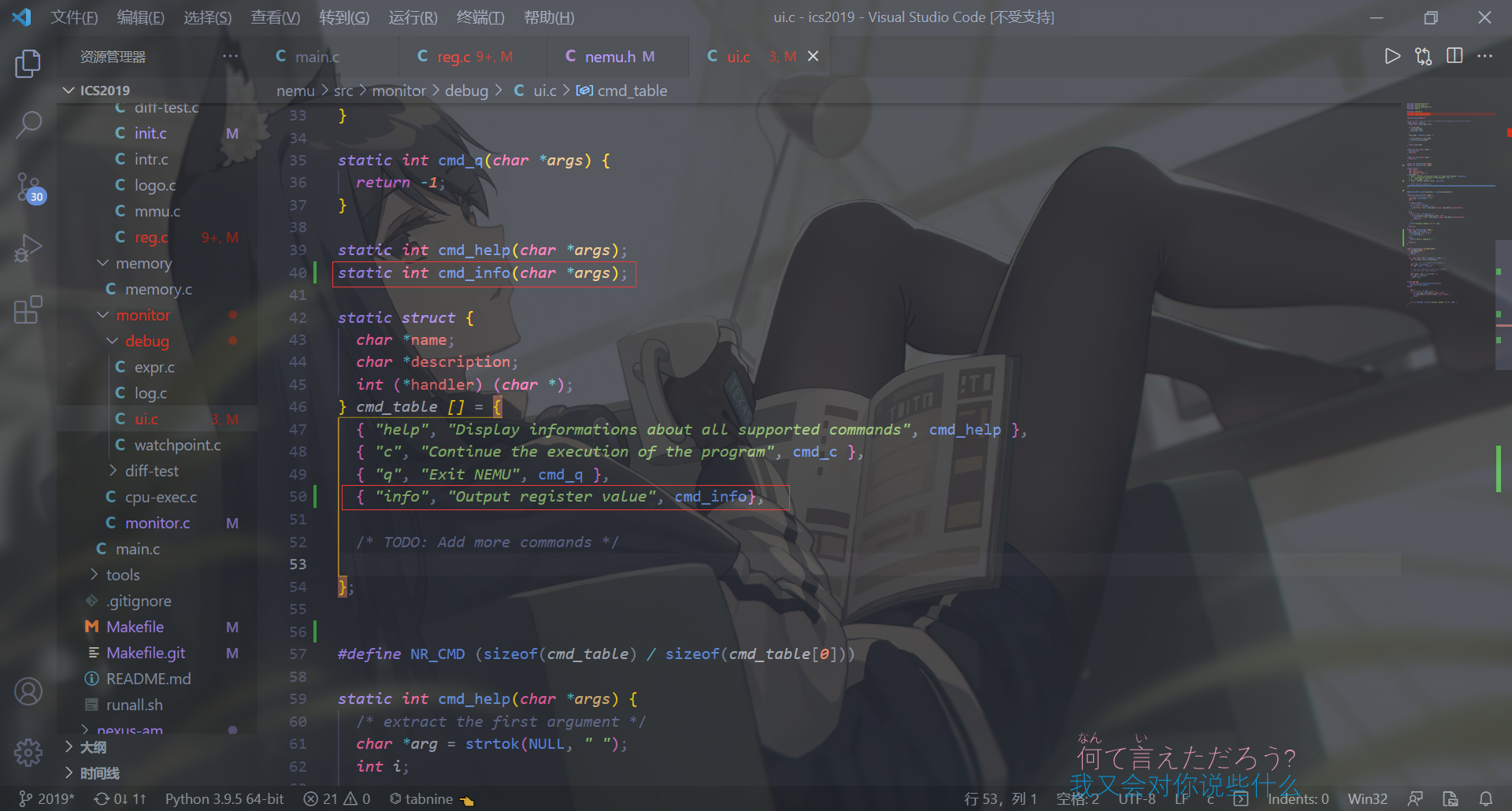
作业2 实现cmd_info
首先在头文件nemu\include\nemu.h中声明isa_reg_display函数
1 2 3 4 5 6 7 8 #ifndef __NEMU_H__ #define __NEMU_H__ #include "common.h" #include "memory/memory.h" #include "isa/reg.h" extern CPU_state cpu;extern void isa_reg_display () #endif
然后在nemu\src\monitor\debug\ui.c实现cmd_info函数(记得在前面声明)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static int cmd_info (char *args) if (args == NULL ) { printf ("Please input the info r\n" ); return 0 ; } char *arg = strtok(NULL , " " ); if (strtok(NULL , " " )!=NULL ) { printf ("Too many parameters\n" ); return 0 ; } if (strcmp (arg, "r" ) == 0 ) { isa_reg_display(); } else { printf ("Info is imperfect\n" ); } return 0 ; }
后面的声明将不会再举例子
1 2 3 4 5 6 7 8 9 10 11 void isa_reg_display () printf ("EAX:0x%x\n" ,cpu.eax); printf ("ECX:0x%x\n" ,cpu.ecx); printf ("EDX:0x%x\n" ,cpu.edx); printf ("EBX:0x%x\n" ,cpu.ebx); printf ("ESP:0x%x\n" ,cpu.esp); printf ("EBP:0x%x\n" ,cpu.ebp); printf ("ESI:0x%x\n" ,cpu.esi); printf ("EDI:0x%x\n" ,cpu.edi); return ; }
cmd_si
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static int cmd_si (char *args) if (args == NULL ) { cpu_exec(1 ); return 0 ; } int step = atoi(strtok(NULL , " " )); if (strtok(NULL , " " )!=NULL ) { printf ("Too many parameters\n" ); return 0 ; } if (step<=0 || step >=999 ) { printf ("Wrong parameter\n" ); return 0 ; } cpu_exec(step); return 0 ; }
cmd_x
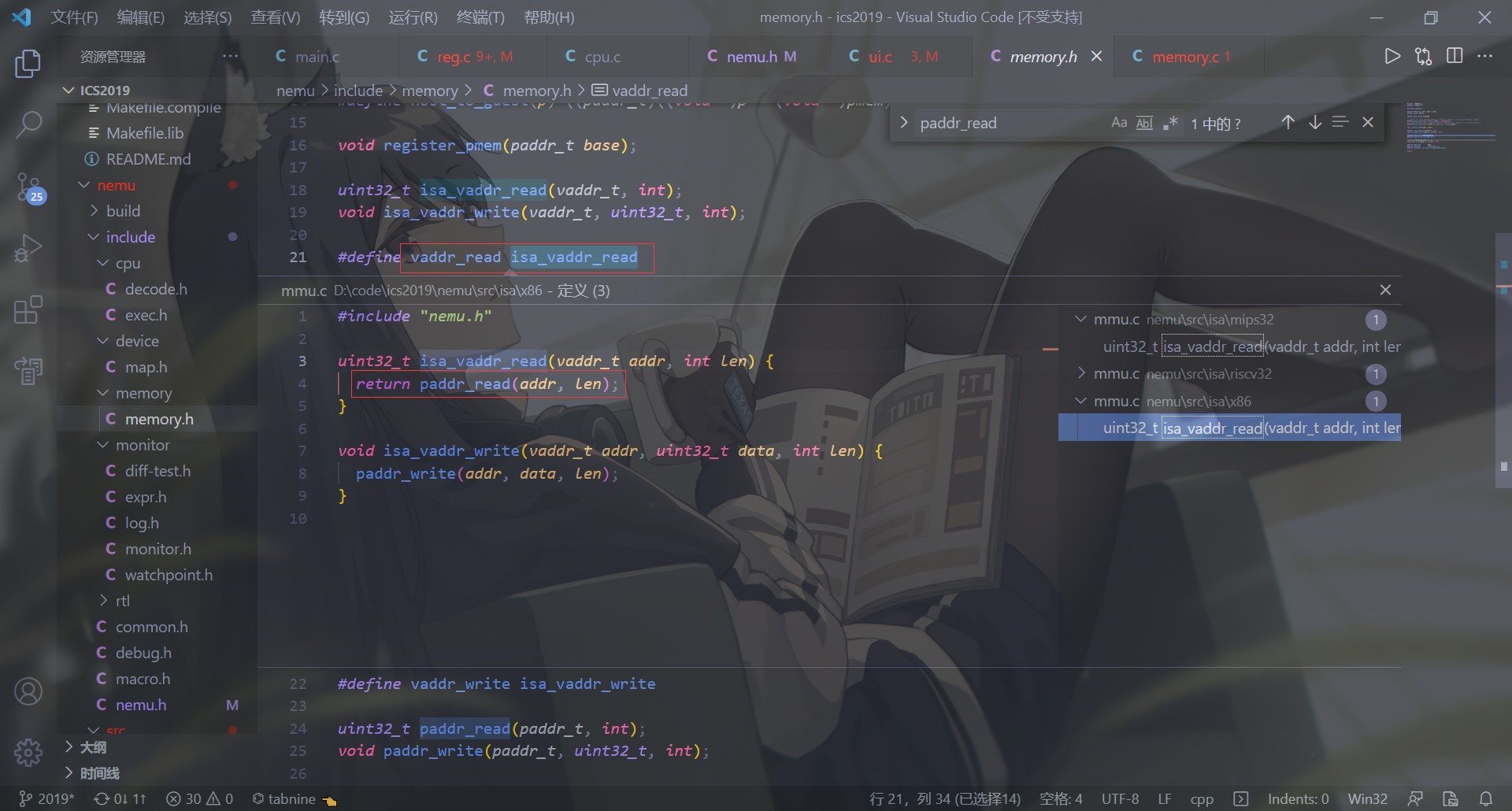
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static int cmd_x (char *args) if (args == NULL ) { printf ("No parameters\n" ); return 0 ; } int count = atoi(strtok(NULL , " " )); if (count==0 ) { printf ("Wrong parameter1\n" ); return 0 ; } char * EXPR_BUFFER = strtok(NULL , " " ); if (EXPR_BUFFER==NULL ) { printf ("Wrong parameter2\n" ); return 0 ; } int EXPR = strtol(EXPR_BUFFER,NULL ,16 ); if (EXPR==0 ) { printf ("Wrong parameter2\n" ); return 0 ; } if (strtok(NULL , " " )!=NULL ) { printf ("Too many parameters\n" ); return 0 ; } for (int i=0 ; i<count; i++) { printf ("0x%x: 0x%x\n" , EXPR+i*5 , paddr_read(EXPR+i*4 , 4 )); } return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 uint32_t paddr_read (paddr_t addr, int len) { if (map_inside(&pmem_map, addr)) { uint32_t offset = addr - pmem_map.low; return *(uint32_t *)(pmem + offset) & (~0u >> ((4 - len) << 3 )); } else { return map_read(addr, len, fetch_mmio_map(addr)); } } static IOMap pmem_map = { .name = "pmem" , .space = pmem, .callback = NULL }; static inline bool map_inside (IOMap *map , paddr_t addr) return (addr >= map ->low && addr <= map ->high); } uint32_t map_read (paddr_t addr, int len, IOMap *map ) assert(len >= 1 && len <= 4 ); check_bound(map , addr); uint32_t offset = addr - map ->low; invoke_callback(map ->callback, offset, len, false ); uint32_t data = *(uint32_t *)(map ->space + offset) & (~0u >> ((4 - len) << 3 )); return data; } IOMap* fetch_mmio_map (paddr_t addr) { int mapid = find_mapid_by_addr(maps, nr_map, addr); return (mapid == -1 ? NULL : &maps[mapid]); }
5.)表达式求值 首先识别出表达式中的单元,然后根据表达式的归纳定义进行递归求值。
词法分析 词法分析就是识别出表达式中有独立含义的子串,它们也被称为token。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #define NR_REGEX (sizeof(rules) / sizeof(rules[0]) ) enum { TK_NOTYPE = 256 , TK_DEC, TK_NEG }; static struct rule { char *regex; int token_type; } rules[] = { {"[0-9]+" , TK_DEC}, {" +" , TK_NOTYPE}, {"\\*" , '*' }, {"/" , '/' }, {"\\(" , '(' }, {"\\)" , ')' }, {"-" , '-' }, {"\\+" , '+' }, }; static regex_t re[NR_REGEX] = {};void init_regex () int i; char error_msg[128 ]; int ret; for (i = 0 ; i < NR_REGEX; i ++) { ret = regcomp(&re[i], rules[i].regex, REG_EXTENDED); if (ret != 0 ) { regerror(ret, &re[i], error_msg, 128 ); panic("regex compilation failed: %s\n%s" , error_msg, rules[i].regex); } } }
int regcomp(regex_t *preg, const char *regex,int cflags);
在一个字符串与正则表达式进行比较之前,首先用regcomp函数对其进行编译,将regex转换为regex_t结构,然后填充到preg中,函数成功则返回0。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 static bool make_token (char *e) int position = 0 ; int i; regmatch_t pmatch; nr_token = 0 ; while (e[position] != '\0' ) { for (i = 0 ; i < NR_REGEX; i ++) { if (regexec(&re[i], e + position, 1 , &pmatch, 0 ) == 0 && pmatch.rm_so == 0 ) { char *substr_start = e + position; int substr_len = pmatch.rm_eo; Log("match rules[%d] = \"%s\" at position %d with len %d: %.*s" , i, rules[i].regex, position, substr_len, substr_len, substr_start); position += substr_len; switch (rules[i].token_type) { case '+' : case '-' : case ')' : case '(' : case '/' : case '*' : case TK_DEC: tokens[nr_token].type = rules[i].token_type; strncpy (tokens[nr_token++].str, substr_start, substr_len); tokens[nr_token].str[substr_len] = '\0' ; break ; case TK_NOTYPE: break ; } break ; } } if (i == NR_REGEX) { printf ("no match at position %d\n%s\n%*.s^\n" , position, e, position, "" ); return false ; } } return true ; }
int regexec(const regex_t *preg, const char *string, size_t nmatch,regmatch_t pmatch[], int eflags);
参数preg指向编译后的正则表达式,参数string是将要进行匹配的字符串。在匹配结束后,nmatch告诉regexec函数最多可以把多少匹配结果填充到pmatch数组中,在匹配结束后,string+pmatch[0].rm_so到string+pmatch[0].rm_eo是第一个匹配的字符串,以此类推。
递归求值 把待求值表达式中的token都成功识别出来之后,然后就可以进行求值了。
首先通过检查括号,然后找到优先级最低的符号把它变成主运算符,然后通过分治法,把这个主运算符前后的式子分成子表达式分别计算,然后一直递归子表达式即可。
例如1+2+3,主运算符应该是最右边的加号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int check_parentheses (Token* start, Token* end) int sign = 0 ; int count = 0 ; if (start->type!='(' || end->type!=')' ) { return false ; } for (Token* sym = start; sym<end; sym++) { if (sym->type == '(' ) { count++; }else if (sym->type ==')' ) { count--; } if (count==0 ) { sign=1 ; } } if (count==1 &&sign==0 ) { return true ; } if (count==1 &&sign==1 ) { return false ; } panic("Error expression" ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 int eval (Token* start, Token* end) if (start == end) { return atoi(start->str); } else if (check_parentheses(start, end) == true ) { return eval(start + 1 , end - 1 ); } else { int val1,val2=0 ; Token *op = clac(start, end); val1 = eval(start, op - 1 ); val2 = eval(op + 1 , end); switch (op->type) { case '+' : return val1 + val2; case '-' : return val1 - val2; case '*' : return val1 * val2; case '/' : return val1 / val2; default : panic("Error expression" ); } } } int calc (Token* start, Token* end) int sign = 0 ; int count = 0 ; Token* op = NULL ; for (Token* sym = start; sym<=end; sym++) { if (sym->type=='(' ) { count++; continue ; } if (sym->type==')' ) { count--; continue ; } if (count!=0 ) { continue ; } if (sym->type==TK_DEC) { continue ; } if (sign<=1 &&(sym->type=='+' ||sym->type=='-' )) { op=sym; sign = 1 ; } else if (sign==0 &&(sym->type=='*' ||sym->type=='/' )) { op=sym; } } return op; }
在递归求值的过程中,逻辑做了两件事情,第一件事情是根据token来分析表达式的结构(找到优先级最低的运算符),然后才是求值。它们在编译器中对应着语法分析,不过编译器分析的是程序的结构,编译器会使用一种框架来分析。
添加负数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Token *op = calc_op(start, end); if (op->type != TK_NEG) { val1 = eval(start, op - 1 ); } val2 = eval(op + 1 , end); switch (op->type) { case '+' : return val1 + val2; case '-' : return val1 - val2; case '*' : return val1 * val2; case '/' : return val1 / val2; case TK_NEG : return val2*-1 ; default : panic("Error expression" ); if (sign<=2 &&(sym->type=='+' ||sym->type=='-' )) { op=sym; sign = 2 ; } else if (sign<=1 &&(sym->type=='*' ||sym->type=='/' )) { op=sym; sign=1 ; }else if (sign==0 &&(sym->type==TK_NEG)) { op=sym; }
1 2 3 4 5 6 7 8 9 10 void check_Negative (Token* start, Token* end) Token* op = start; for (; start<=end; start++) { if (start->type=='-' && (start-1 )->type!=TK_DEC && (start-1 )->type!=')' ) { start->type=TK_NEG; } } start=op; return ; }
如何测试你的代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 static int count=0 ;static char buf[60000 ];static char code_buf[65536 ];static char *code_format ="#include <stdio.h>\n" "int main() { " " unsigned result = %s; " " printf(\"%%u\", result); " " return 0; " "}" ;static int choose (unsigned int i) return rand()%i; } static void gen_num () int i=choose(65536 ); sprintf (buf+count, "%d" , i); while (buf[count]) { count++; } } static void gen_rand_op () switch (choose(4 )) { case 0 : sprintf (buf+count, "%c" , '+' ); break ; case 1 : sprintf (buf+count, "%c" , '-' ); break ; case 2 : sprintf (buf+count, "%c" , '*' ); break ; case 3 : sprintf (buf+count, "%c" , '/' ); break ; } count++; } static void gen (char c) sprintf (buf+count, "%c" , c); count++; } static inline void gen_rand_expr () int i = choose(3 ); if (count>20 ) { i = 0 ; } switch (i) { case 0 : gen_num(); break ; case 1 : gen('(' ); gen_rand_expr(); gen(')' ); break ; default : gen_rand_expr(); gen_rand_op(); gen_rand_expr(); break ; } } int main (int argc, char *argv[]) int seed = time(0 ); srand(seed); int loop = 1 ; if (argc > 1 ) { sscanf (argv[1 ], "%d" , &loop); } int i; for (i = 0 ; i < loop; i ++) { gen_rand_expr(); sprintf (code_buf, code_format, buf); FILE *fp = fopen("/tmp/.code.c" , "w" ); assert(fp != NULL ); fputs (code_buf, fp); fclose(fp); int ret = system("gcc /tmp/.code.c -o /tmp/.expr" ); if (ret != 0 ) continue ; fp = popen("/tmp/.expr" , "r" ); assert(fp != NULL ); int result; fscanf (fp, "%d" , &result); pclose(fp); printf ("%u %s\n" , result, buf); } return 0 ; }
cmd_p和expr 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 uint32_t expr (char *e, bool *success) if (!make_token(e)) { *success = false ; return 0 ; } int num = eval(tokens,tokens+nr_token-1 ); return num; } static int cmd_p (char *args) if (args == NULL ) { printf ("No parameters\n" ); return 0 ; } bool success = true ; int num = expr(args,&success); if (success==false ) { printf ("Wrong expression\n" ); return 0 ; }else { printf ("0x%x or %dD\n" ,num,num); return 0 ; } }
6.)监视点
如果前面的代码看明白了,这里的扩展会十分好写。所以我就不直接放代码了,如果实在是写不出来可以去github看,请务必学习思路,而不是抄代码。同时我也会逐渐在文章中减少代码,只放关键代码。
写的时候请注意如下一点,然后实现指针的时候可以用vaddr_read这个函数(内置)。
1 2 3 4 5 6 7 8 static struct rule { char *regex; int token_type; } rules[] = { {"!=" , '!=' }, }
监视点的功能是监视一个表达式的值何时发生变化,我们首先实现两个函数
1 2 WP* new_wp () ;void free_wp (WP *wp)
其中new_wp()从free_链表中返回一个空闲的监视点结构,free_wp()将wp归还到free_链表中,这两个函数会作为监视点池的接口被其它函数调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 void init_wp_pool () int i; for (i = 0 ; i < NR_WP; i ++) { wp_pool[i].NO = i; wp_pool[i].next = &wp_pool[i + 1 ]; } wp_pool[NR_WP - 1 ].next = NULL ; head = NULL ; free_ = wp_pool; } WP* new_wp () { if (!free_) { panic("Error: Wp_pool is empty!\n" ); } WP *tmp = free_; free_ = free_->next; tmp->next = head; head = tmp; return tmp; } void free_wp (WP *wp) if (!wp) return ; int flag = 0 ; WP *tmp = head; for (;tmp;tmp = tmp->next, flag++){ if (tmp == wp) break ; } if (!tmp) return ; if (flag == 0 ) head = head->next; else { tmp = head; for (int i = 0 ; i < flag-1 ; i++){ tmp = tmp->next; } tmp->next = tmp->next->next; } wp->next = free_; free_ = wp; }
这里的free_可以理解为空element。用于释放时把已经使用过的element变成空闲状态。
另外free_一共有32个,最后一个的next指向null的地址,他们组成一个链表池。tmp是我们自己使用的链表,所谓的new_wp就是在free_链表池中给tmp一个空间。
1 2 3 4 5 6 7 free_链表池 NO: 0 1 2 3 ... 31 NULL NEXT: &1 &2 &3 &4 ... NULL NULL ______________________________________ 我们自己用的tmp池 NO: NULL 0 1 2 3 ... 31 NEXT: NULL NULL &0 &1 &2 ... &30
剩下的代码实现请去找github吧,可以检测一下你对整个代码的熟悉程度
思路:
首先检测表达式是不是正确的,如果是正确的就分配一个链表element存入表达式和结果。然后每执行一条指令,就计算一次表达式,跟之前的结果进行比对,如果结果不一致则暂停NEMU_STOP。
如果看过代码后会发现其实很简单,尽管这段我是直接照抄的,还是建议大家参考思路写代码。在cpu_exec函数中给大家留下了监视点的判断比对空间。
有关断点 PA给的学习链接 ,也可以直接看我写的文章 异常控制流那章
int3指令是陷阱指令,它生成一个单字节操作码cc,这样的好处是可以用int3替换任何指令。
PA2-简单复杂的机器
task PA2.1: 在NEMU中运行第一个C程序dummy
task PA2.2: 实现更多的指令, 在NEMU中运行所有cputest
task PA2.3: 运行打字小游戏, 提交完整的实验报告
在PA1中, 我们已经见识到最简单的计算机TRM的工作方式:
1 2 3 4 5 while (1 ) { 从PC指示的存储器位置取出指令; 执行指令; 更新PC; }
取指:取指令要做的事情就是将PC指向的指令从内存读入到CPU中
译码:CPU拿到一条指令之后, 可以通过查表的方式得知这条指令的操作数和操作码
执行:例如把两个操作数放入加法器,然后得到执行结果,再放回目的操作数中(可能是寄存器或者内存)
更新:执行完一条指令后,CPU就会执行下一条指令。CPU会让PC加上刚才执行完的指令的长度, 即可指向下一条指令的位置
1.)取指令,译码,执行 1 2 3 4 5 6 7 8 9 10 11 12 typedef struct { uint32_t opcode; uint32_t width; vaddr_t seq_pc; bool is_jmp; vaddr_t jmp_pc; Operand src, dest, src2; struct ISADecodeInfo isa ; } DecodeInfo; DecodeInfo decinfo;
1 2 __attribute__((unused)) vaddr_t seq_pc = exec_once();
1 2 3 4 5 6 vaddr_t exec_once (void ) decinfo.seq_pc = cpu.pc; isa_exec(&decinfo.seq_pc); update_pc(); return decinfo.seq_pc; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 void isa_exec (vaddr_t *pc) uint32_t opcode = instr_fetch(pc, 1 ); decinfo.opcode = opcode; set_width(opcode_table[opcode].width); idex(pc, &opcode_table[opcode]); } static inline uint32_t instr_fetch (vaddr_t *pc, int len) uint32_t instr = vaddr_read(*pc, len); #ifdef DEBUG uint8_t *p_instr = (void *)&instr; int i; for (i = 0 ; i < len; i ++) { extern char log_bytebuf[]; strcatf(log_bytebuf, "%02x " , p_instr[i]); } #endif (*pc) += len; return instr; } static inline void set_width (int width) if (width == 0 ) { width = decinfo.isa.is_operand_size_16 ? 2 : 4 ; } decinfo.src.width = decinfo.dest.width = decinfo.src2.width = width; } typedef struct { DHelper decode; EHelper execute; int width; } OpcodeEntry; #define make_DHelper(name) void concat(decode_, name) (vaddr_t *pc) typedef void (*DHelper) (vaddr_t *) #define make_EHelper(name) void concat(exec_, name) (vaddr_t *pc) typedef void (*EHelper) (vaddr_t *) #define concat_temp(x, y) x ## y #define concat(x, y) concat_temp(x, y) static inline void idex (vaddr_t *pc, OpcodeEntry *e) if (e->decode) e->decode(pc); e->execute(pc); }
不要copy-paste
大家在实现指令的时候,不要把已有的代码复制好几份,然后进行一些的改动。这样如果一旦有一个代码出现问题,将会非常难以调试。
RTL(寄存器传输语言) 在nemu中,RTL寄存器统一使用rtlreg_t定义
1 typedef uint32_t rtlreg_t ;
不同ISA的通用寄存器(在nemu/src/isa/$ISA/include/isa/reg.h中定义)
id_src,id_src2和id_dest中的访存地址addr和操作数内容val(在nemu/include/cpu/decode.h中定义)。临时寄存器s0, s1, t0, t1和ir(在nemu/src/cpu/cpu.c中定义)
RTL基本指令(在nemu/include/rtl/rtl.h中定义),它们的特点是不需要使用临时寄存器,只是CPU执行过程中最基本的操作,所以不同的ISA都可以使用RTL基本指令。与ISA相关的指令在nemu/src/isa/$ISA/include/isa/rtl.h定义。
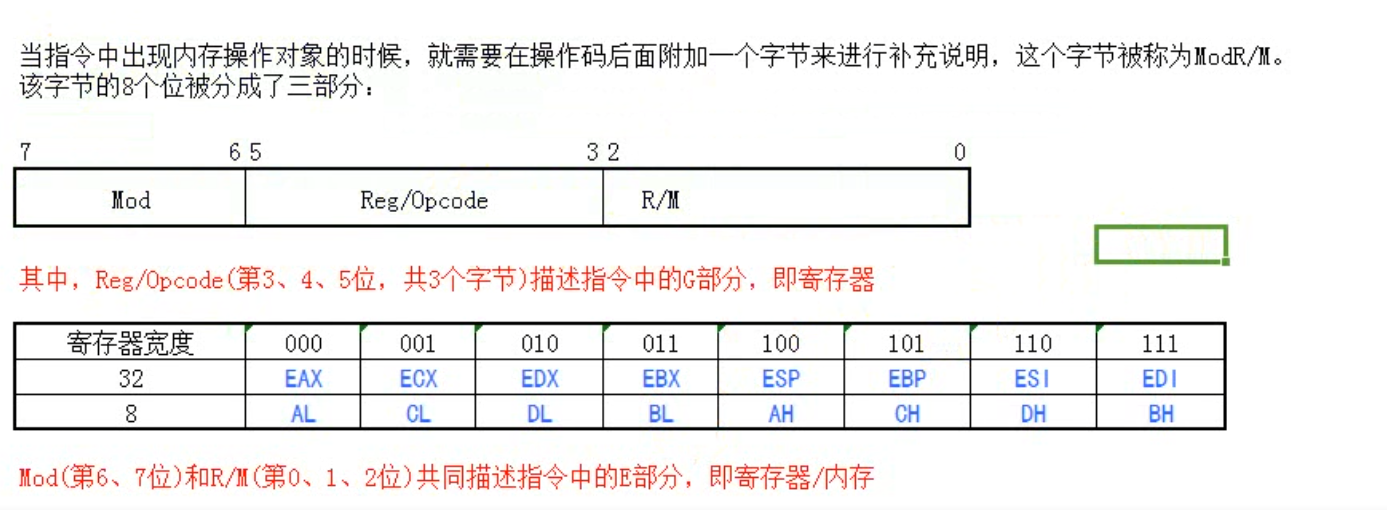
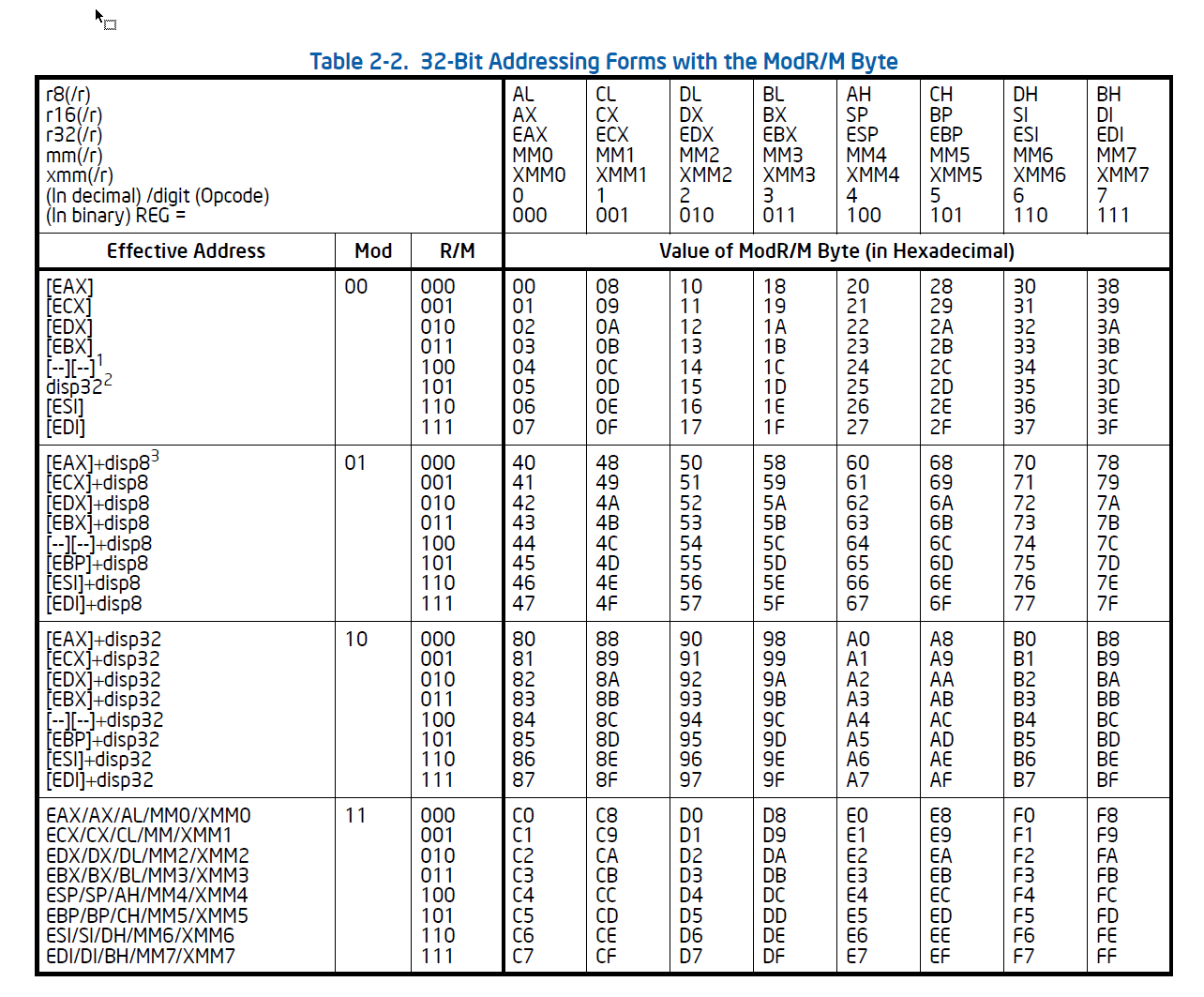
2.)i386 x86指令的一般格式
1 2 3 4 5 6 7 8 +-----------+-----------+-----------+--------+------+------+------+------------+-----------+ |instruction| address- | operand- |segment |opcode|ModR/M| SIB |displacement| immediate | | prefix |size prefix|size prefix|override| | | | | | |-----------+-----------+-----------+--------+------+------+------+------------+-----------| | 0 OR 1 | 0 OR 1 | 0 OR 1 | 0 OR 1 |1 OR 2|0 OR 1|0 OR 1| 0,1,2 OR 4 |0,1,2 OR 4 | | - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -| | number of bytes | +------------------------------------------------------------------------------------------+
除了opcode操作码必定出现以外,其余部分都有可能不出现。
PA中的x86经过简化, address-size prefix和segment override prefix都不会用到
16位的就是去掉e
当mod的值是111时,r/m取寄存器;否则r/m表示内存。
如果operand-size prefix的编码是0x66,表示操作数宽度就要改变成16位,否则默认是32位。
因为PA没有段,所以段偏移全部变成相对于物理地址0处的偏移量。
作业3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 /root/ics2019/nexus-am/tests/cputest/build/dummy-x86-nemu.elf: file format elf32-i386 Disassembly of section .text: 00100000 <_start>: 100000 : bd 00 00 00 00 mov $0x0 ,%ebp 100005 : bc 00 90 10 00 mov $0x109000 ,%esp 10000 a: e8 05 00 00 00 call 100014 <_trm_init> 10000f : 90 nop 00100010 <main>: 100010 : 31 c0 xor %eax,%eax 100012 : c3 ret 100013 : 90 nop 00100014 <_trm_init>: 100014 : 55 push %ebp 100015 : 89 e5 mov %esp,%ebp 100017 : 83 ec 14 sub $0x14 ,%esp 10001 a: 68 00 00 00 00 push $0x0 10001f : e8 ec ff ff ff call 100010 <main> 100024 : d6 (bad) 100025 : 83 c4 10 add $0x10 ,%esp 100028 : eb fe jmp 100028 <_trm_init+0x14 >
这个是dummy在nemu中运行所需的。我们需要实现call,push,sub,xor,ret五条指令。
指令
编码
描述
call
e8
push
68
sub
83
xor
31
ret
c3
果咩,因为我没看懂pa2这段代码,所以决定不浪费时间跑路了