堆学习
0x00 堆的概述
根据内存的需求不同,堆的实现也有很多种:
1 | dlmalloc – General purpose allocator |
堆是程序虚拟地址空间的一块连续的线性区域,它由低地址向高地址方向增长。(栈由高地址向低地址方向增长)
管理堆的程序被我们称为堆管理器,堆管理器处于用户程序和内核中间,主要做以下工作:
- 用户程序申请内存的时候,堆管理器会向操作系统申请内存,然后返回给用户程序。
为了保证内存管理的高效性质,内核一般会预先分配很大一块连续内存作为堆,只有当堆空间不足的时候,堆管理器才会与操作系统进行交互。 - 管理用户所释放的内存。
一般来说,用户释放的内存空间并不会直接返还给操作系统,而是由堆管理器进行管理,这些内存可以用来响应用户新申请的内存请求。
malloc
1 | /* |
- malloc 函数返回对应大小字节的内存块的指针
- 当n=0时,返回当前系统允许的堆的最小内存块
- size_t 是无符号数,当n为负数时,会申请很大的内存空间,但通常都会失败
1 | void *ptr=malloc(0x10); |
系统开始是不分配堆空间的,当你调用malloc函数在内存中申请空间时,系统才会开辟一大片空间作为堆的分配使用空间。malloc函数再从这一片堆的分配使用空间中分配0x10大小的空间,将指向空间的地址返回给ptr(剩下的空间为topchunk)。
free
1 | /* |
- free 函数会释放由 p 所指向的内存块
- 当 p 为空指针时,函数不执行任何操作
- 当p已经被释放之后,再次释放会出现乱七八糟的效果,这就是
double free。 - 当释放很大的内存空间时,程序会将这些内存空间还给系统,以便于减小程序所使用的内存空间。
(s)brk
我们可以通过增加brk(program break)的大小来向操作系统申请内存。
初始时,堆的起始地址 start_brk 以及堆的当前末尾 brk 指向同一地址。根据是否开启ASLR,两者的具体位置会有所不同:
- 不开启ASLR,start_brk 以及 brk 会指向 data/bss 段的结尾。
- 开启ASLR, start_brk 以及 brk 也会指向同一位置,只是这个位置是在 data/bss 段结尾后的随机偏移处。
mmap
malloc 会使用 mmap 来创建独立的匿名映射段。匿名映射的目的主要是可以申请以 0 填充的内存,并且这块内存仅被调用进程所使用。
多线程与Arena
1 | struct malloc_state { |
不是每一个线程都有自己的arena。
arena是一段连续的堆内存区域,主线程申请的arena叫做main_arena,只有main_arena可以访问heap段和mmap映射区域。子线程申请的non_main_arena只能访问mmap映射区域。
当arena没有足够的空间时,系统就会执行mmap函数来分配相应的内存空间。这与这个请求来自于主线程还是从子线程无关。
0x01 堆相关的数据结构
malloc_chunk
- malloc 申请的内存在 ptmalloc 内部用malloc_chunk 结构体表示
- 当程序申请的 chunk 被 free 后,会被加入到相应的空闲管理列表中

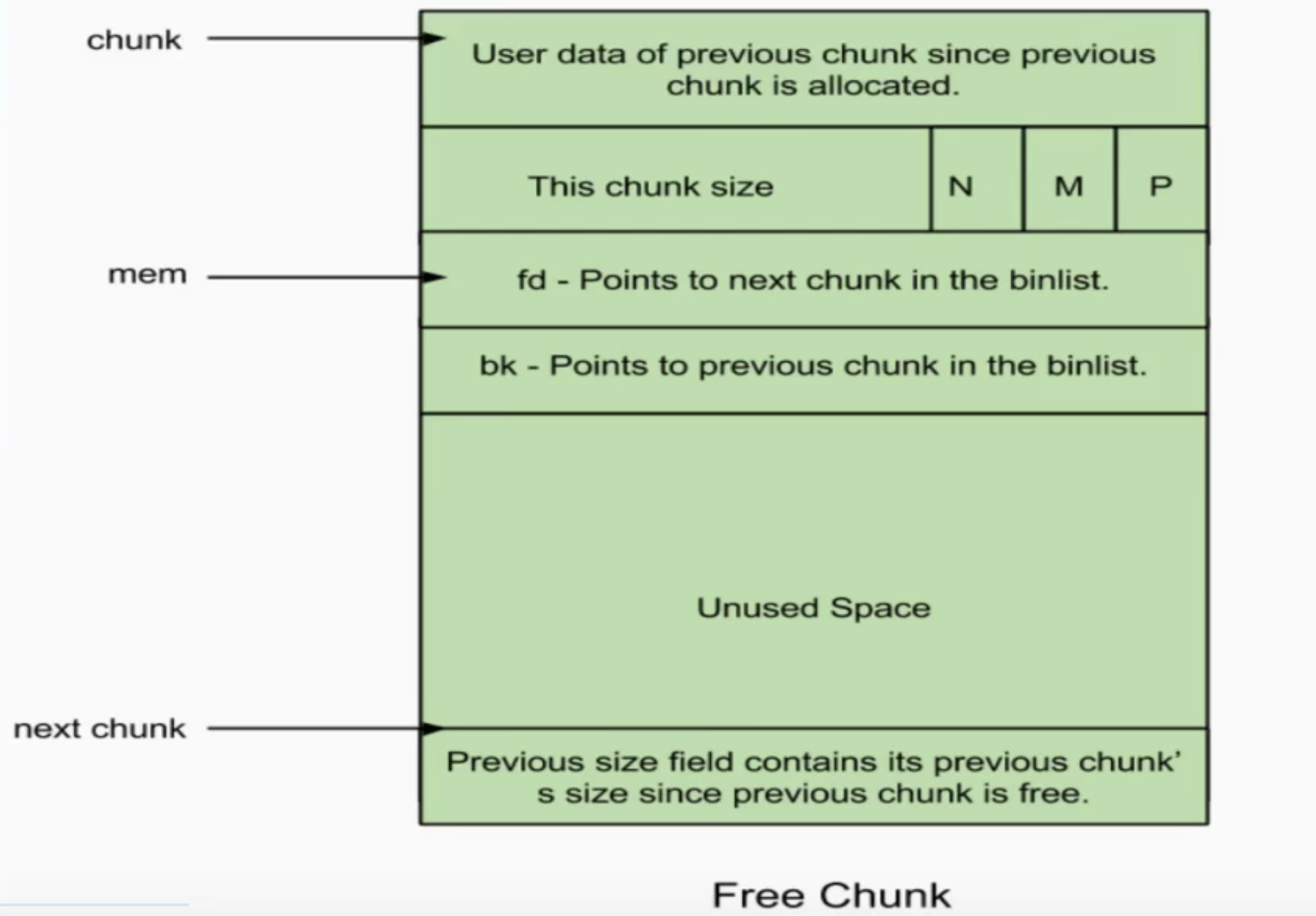
无论一个 chunk 的大小如何,处于分配状态还是释放状态,它们都使用一个统一的结构,但是根据是否被释放,它们的表现形式会有所不同。
1 | /* |
prev_size:如果该chunk的物理相邻的前一地址chunk(两个指针的地址差值为前一chunk大小)是空闲的话,那这个字段记录的是前一个chunk的大小(包括chunk头)。否则存储物理相邻的前一个(较低地址)chunk的数据。
size:该chunk的大小,大小必须是 2 * SIZE_SZ 的整数倍。如果申请的内存大小不是 2 * SIZE_SZ 的整数倍,会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。
该字段的低三个比特位对 chunk 的大小没有影响,它们从高到低分别表示:
- NON_MAIN_ARENA:记录当前 chunk 是否不属于主线程,1 表示不属于,0 表示属于。
- IS_MAPPED:记录当前 chunk 是否是由 mmap 分配的。
- PREV_INUSE:记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
fd,bk:chunk处于分配状态时,从fd字段开始是用户的数据。chunk处于空闲状态时,会被添加到对应的空闲管理链表中。
fd指向下一个(非物理相邻)空闲的chunk,bk指向上一个(非物理相邻)空闲的chunk。通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理
fd_nextsize,bk_nextsize:只有 chunk 空闲的时候才使用,用于较大的chunk。
- fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。

size的大小必须是size_t*2,所以低三位用不到,因为最低位数也应该是1000b
-8是因为prev_size的复用。
获得前一个chunk的地址:当前chunk的地址-prev_size=前一个chunk的地址
一个已经分配的 chunk 的样子如下。前两个字段称为 chunk header,后面的部分称为 user data。每次 malloc 申请得到的内存指针,指向 user data 的起始处。
1 | chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
被释放的 chunk 被记录在链表中(可能是循环双向链表,也可能是单向链表)。具体结构如下
1 | chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
如果一个 chunk 处于 free 状态,那么它本身的 size 字段和 chunk 字段都会记录。
一般情况下,物理相邻的两个空闲 chunk 会被合并为一个 chunk 。堆管理器会通过 prev_size 字段以及 size 字段合并两个物理相邻的空闲 chunk 块。

分配0x10的空间和分配0x18的空间其实是一样的,都会分配0x20。因为prev_size可以给前面的chunk使用,所以会多8。
bin
ptmalloc 会统一管理 heap 和 mmap 映射区域中的空闲的 chunk,当用户再一次请求分配内存时,ptmalloc 分配器会在空闲的 chunk 中挑选一块合适的给用户,这样可以避免频繁的系统调用,降低内存分配的开销。
glibc提供了两个数组:
fastbinsY拥有10个元素的数组,用于存放每个fast chunk链表头指针,所以fast bins最多包含10个fast chunk的单向链表。最后三个链表保留未使用。
bins用于存放unsorted bins,small bins,large bins的chunk链表头指针,small bins一共62个,large bins一共63个,加起来一共125个bin。
- fastbin:大小范围从0x20-0x80。
fastbinsY - unsortedbin:未归类的bin,临时存储用,存放的堆块大小不一定。
bin[1] - smallbin:大小范围从0x90-0x400。
bin[2]到bin[63] - largebin:大小范围在0x410以上。
bin[64]到bin[126]
除了fastbins之外,其他bins任意两个物理相邻的空闲chunk不能在一起。

堆释放后,会被添加到响应的bins中进行管理,涉及到的结构体是malloc_state。
1 | struct malloc_state { |
空闲的 chunk 根据大小和使用状态被初步分为4类:
fast bins
单向链表,采取 LIFO 策略。最近释放的 chunk 会被更早分配。当用户需要的 chunk 大小小于 fastbin 最大大小时,ptmalloc 会首先判断 fastbin 中相应的 bin 中是否有对应大小的空闲块,如果有就直接从这个 bin 中获取,没有的话,才会进行下一步操作。
fastbin 范围的 chunk 的 prev_inuse 始终被置为 1,因此它们不会和其它被释放的 chunk 合并。
但是当释放的 chunk 与该 chunk 相邻的空闲 chunk 合并后的大小大于 FASTBIN_CONSOLIDATION_THRESHOLD 时,内存碎片可能比较多了,我们就需要把 fast bins 中的 chunk 都进行合并,以减少内存碎片对系统的影响。
chunk大小(含chunk头部)时会把free chunk放到fast bins中:32位0x10-0x40,64位0x20-0x80B。相邻bin存放的大小相差32位0x8(64位0x10)B。
以64位举例子,程序最小分配0x20个空间,因为0x10存放prev_size和size。剩下0x10存放用户空间,也是fd和bk(只有large bin需要fd_nextsize和bk_nextsize)。
1 | /* |
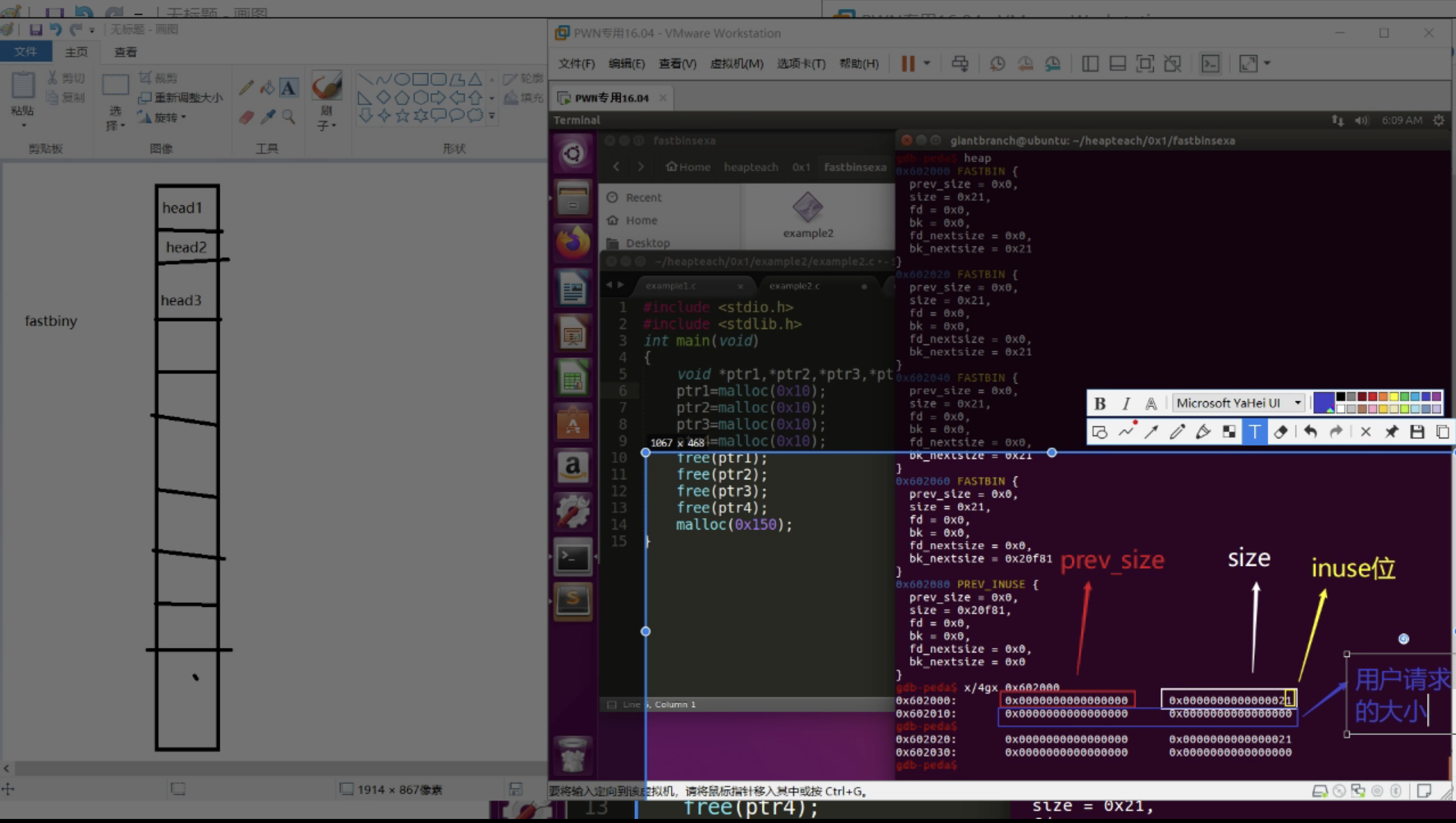
size=申请的0x10+chunk head的0x10。fastbins 范围的 chunk 的 inuse 始终被置为 1。
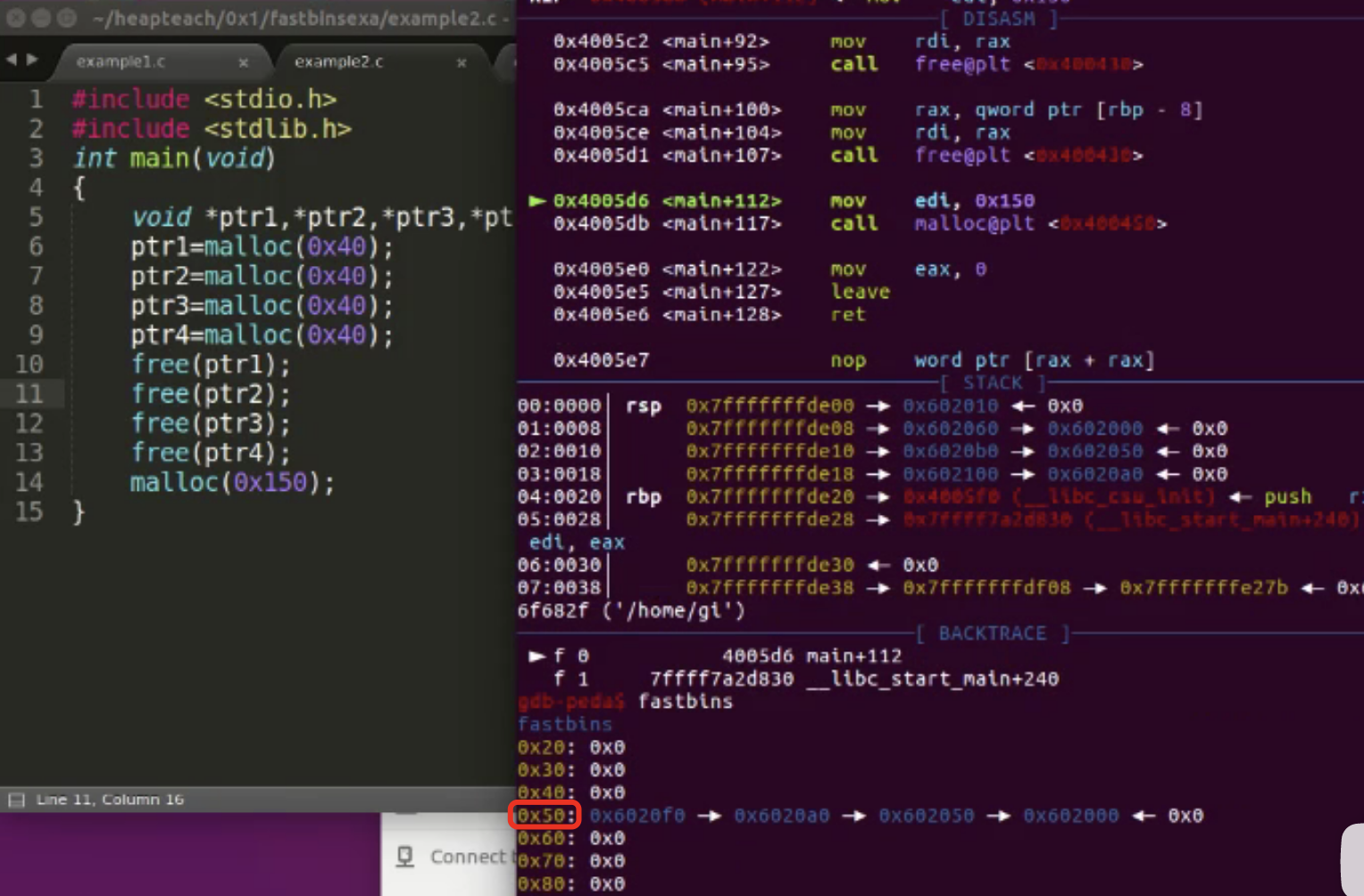
但是如果申请的字节过大,就不会存放在fastbin中
最大能申请的字节是0x78,下图一个申请了0x78,一个申请了0x79。

fastbin匹配算法
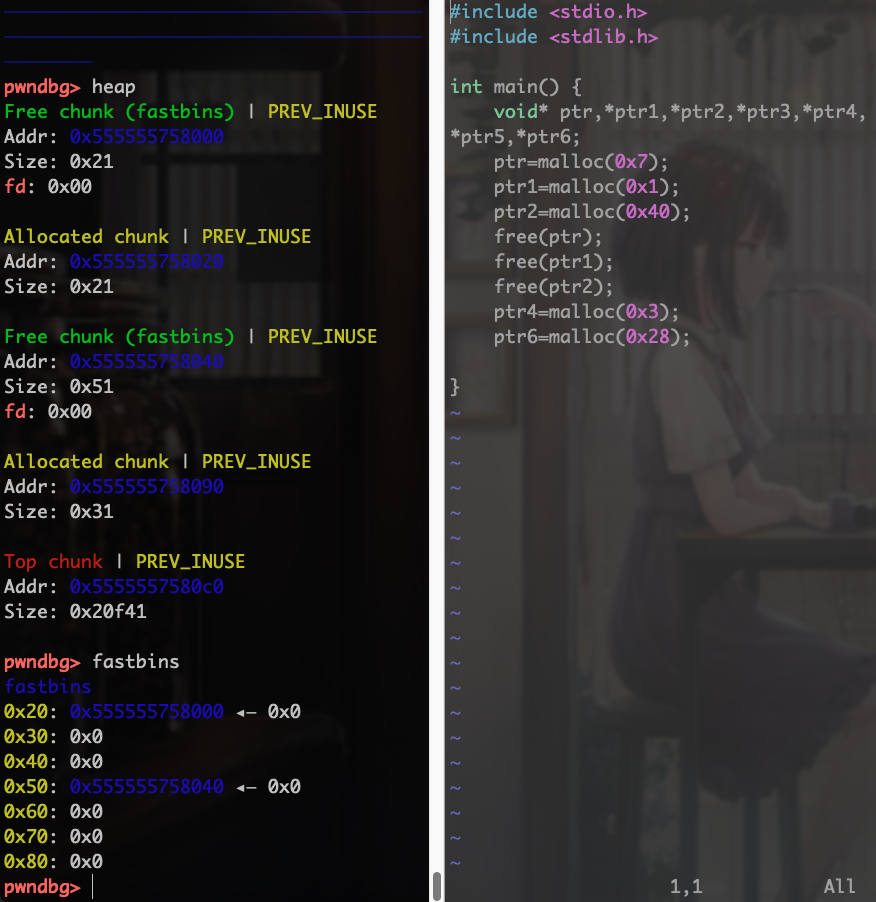
前面说过fastbin有10个链表,但是实际上只会用到3个。每个链表所有的chunk大小都是一样的。
比如下图,在0x50的链表中有一个free chunk,但是新建一个0x30的chunk并不会使用这个0x50的空间,必须是0x50的才会使用。观察一下fastbin链表排列的地址,也可以发现是按分配时间分配的。
unsorted bin
除了fastbin之外,其他的bins只要相邻就会合并。
Unsorted bin 是一个双向循环链表。chunk大小要大于global_max_fast。对于非fastbin大小的chunk被释放时都会首先进入unsorted bin。在unsorted bin为空的时候会进入small bin和large bin。
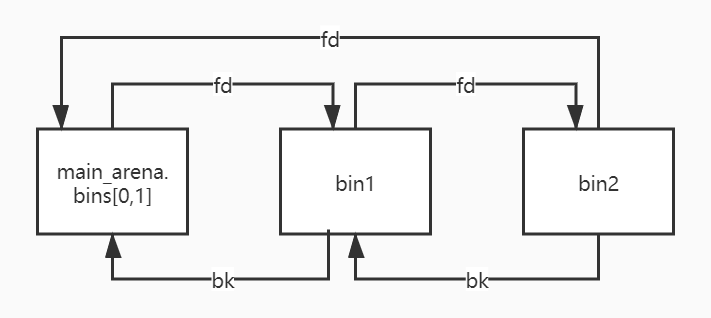
unsorted bin 可以视为空闲 chunk 回归其所属 bin 之前的缓冲区。
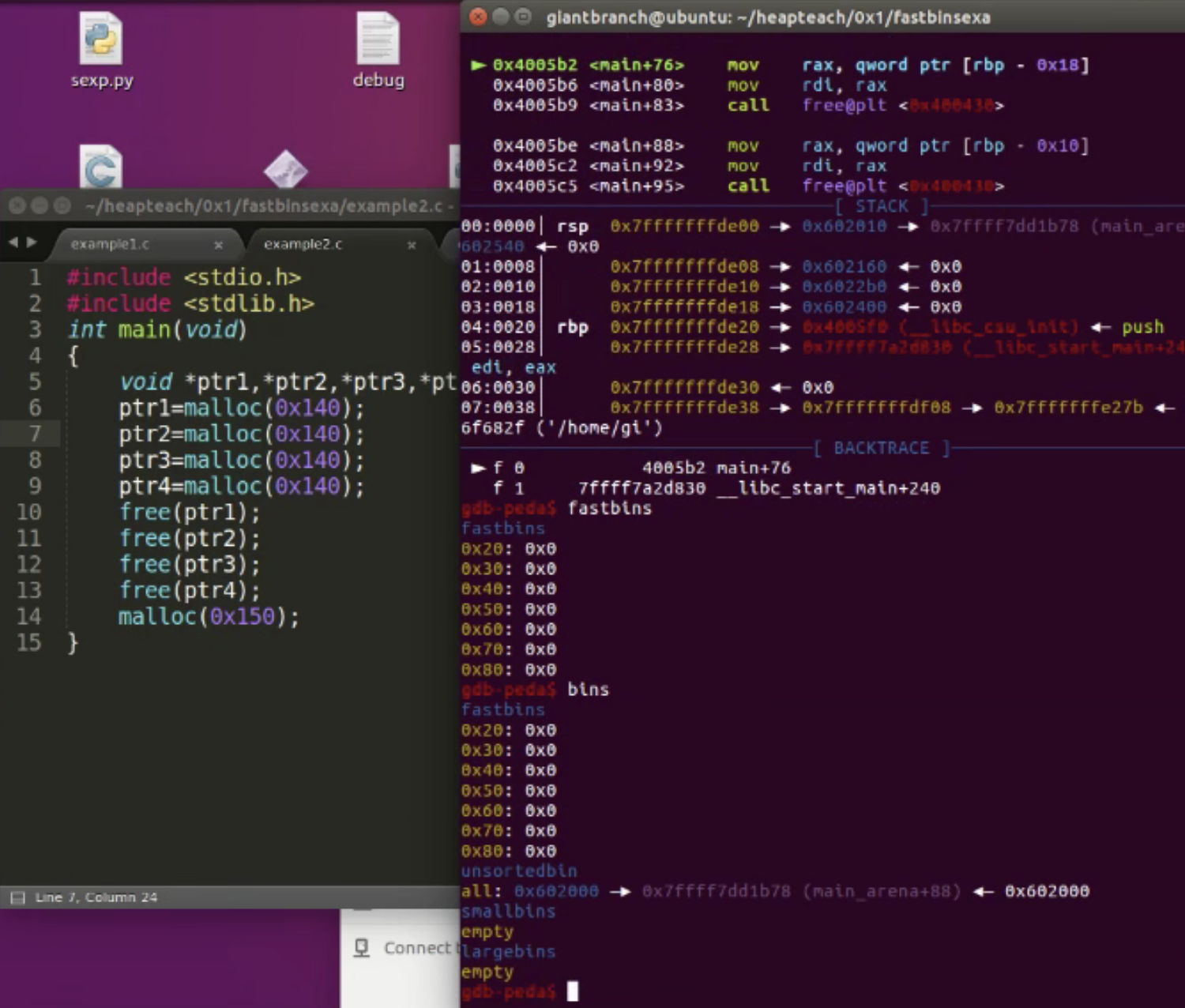

unsorted只有一个,其中保存的chunk大小不固定,unsorted bin的fd和bk指向自身的main_arena+88,我们可以通过uaf漏洞泄漏main_arena真实地址,从而得到libc加载地址。
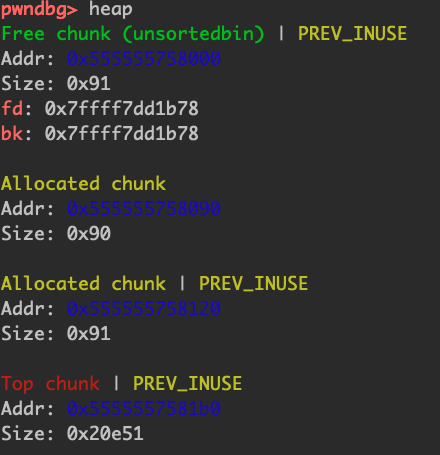
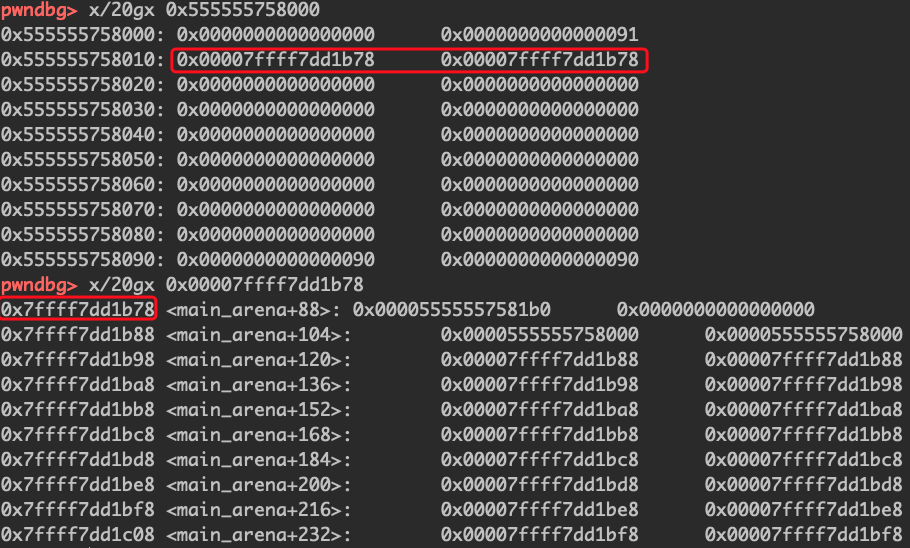
free第二次
会发现是0x90+0x90
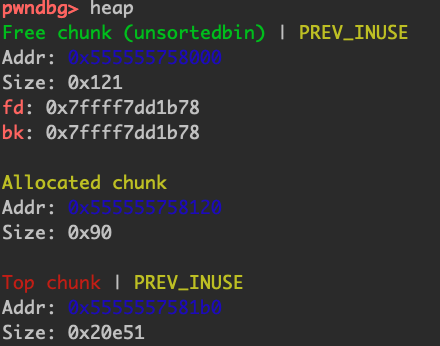
全部free掉会发现全都加到了topchunk里,而且prev_size还是1,fd和bk还是指向main_arena+88的地方。
当只有一个unsorted bin/small bin/large bin的时候,它们的fd和bk指针都会指向main_arena。
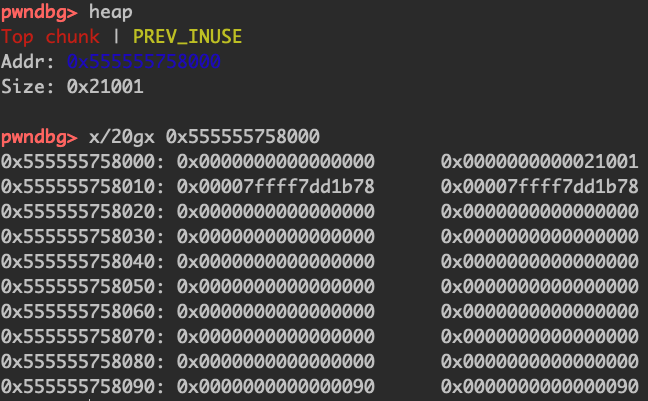
双向链表,main_arena+88是unsorted的第一个chunk
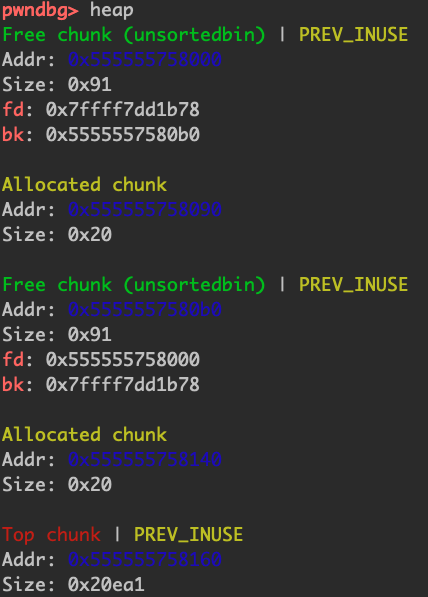
small bins
unsorted bin缓存后,再次malloc分配内存时,会把chunk放到samll bin和large bin中。
small bins保存0x20~0x400字节的chunk,由于是双链表结构,所以速度会比fast bin慢。
small bins 中一共有 62 个双向循环链表,每个链表中存储的 chunk 大小都一致。采用 FIFO 规则。先被释放的 chunk 被先分配出去。两个相邻的small bin中的chunk大小相差SIZE_SZ*2。
small bins 中每个 chunk 的大小与其所在的 bin 的 index 的关系为:chunk_size = 2 * SIZE_SZ *index
它的特点跟fast bins一样,单条链表chunk大小相等,但是small bin会参与合并,切割。
| 下标 | SIZE_SZ=4(32 位) | SIZE_SZ=8(64 位) |
|---|---|---|
| 2 | 16 | 32 |
| 3 | 24 | 48 |
| 4 | 32 | 64 |
| 5 | 40 | 80 |
| x | 2*4*x | 2*8*x |
| 63 | 504 | 1008 |
large bins
大于0x400的chunk使用large bin进行管理。
large bins 中一共包括 63 个 bin,每个 bin 中的 chunk 的大小不一致,处于一定区间范围内。
这 63 个 bin 被分成了 6 组,每组 bin 中的 chunk 大小之间的公差一致
| 组 | 数量 | 公差 |
|---|---|---|
| 1 | 32 | 16*SIZE_SZ |
| 2 | 16 | 32*SIZE_SZ |
| 3 | 8 | 64*SIZE_SZ |
| 4 | 4 | 128*SIZE_SZ |
| 5 | 2 | 256*SIZE_SZ |
| 6 | 1 | 不限制 |
它会以二维双向链表进行维护,对于bin中所有的chunk,相同大小的chunk用fd和bk指针相连,对于不同大小的chunk,采用fd_nextsize和bk_nextsize指针连接。并且沿着fd_nextsize指针,chunk大小递增。
一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适chunk 时挨个遍历。
large bin使用smallest-first,best-fit原则。
Top chunk
程序第一次进行 malloc 的时候,heap 会被分为两块,一块给用户,剩下的那块就是 top chunk。分配整块heap被称作arena。
top chunk 就是堆物理地址最高的 chunk,这个chunk不属于任何一个 bin,它的作用在于当所有 bin 都无法满足用户请求的大小时,如果 top chunk 不小于用户指定大小,就进行分配,将剩余部分作为新的 top chunk。否则就对 heap 进行扩展之后再分配。
topchunk的prev_inuse位总是1,前面在unsorted bin中已经看到过了,在我们malloc的时候,会给我们分配0x21000B的内存。
top_chunk的地址会被记录在main_arena+88的位置
last remainder
在用户使用 malloc 请求分配内存时,ptmalloc2 找到的 chunk 可能和申请的大小内存不一致,这时候我们将分割之后的剩余部分称为 last remainder chunk,unsorted bin 也会存这一块。top chunk 剩余的部分不会作为 last remainder。
hook
__malloc_hook:在malloc之前,它会检查malloc_hook是否为空,如果不为空,那么就会跳到malloc_hook去先执行它
malloc_hook距离main_arena的距离为main_arena-0x10
__free_hook:在free之前,检查free是否为空,如果不为空,就会跳到free_hook去先执行它
tcache(glib 2.26)
tcache的目的是提升堆管理的性能,但是提升性能的同时舍弃了很多安全检测。
- tcache有64个bins,每个bin最多可以存7个chunk。chunk的大小在32bit上是12到512,在64bit上是24到1024(0x400).
- tcache和fastbin类似,都是LIFO且是单向链表。
- 当某一个tcache链表满了7个,再次free会被放到fastbin,满了放到unsorted bin。
- tcache中的chunk不会被合并(标志位不取消)。
- tcache的fd指针指向的不是首地址,指向的是fd。
malloc分配流程
首先用户malloc请求一个内存,先将请求的内存大小转换成chunk大小。
1 | size_t request2size(size_t req){ |
算出chunk_size之后,首先判断chunk_size是否<=global_max_fast,也就是是否在fast bin的范围中。
如果在,会首先寻找匹配的fast bin,如果当前size的fast bin为空,就会寻找small bin,如果再为空,然后会去unsorted bin中寻找合适的chunk。unsorted bin每次遍历一个不满足要求的chunk,就会把它加到合适的small bin或者large bin中。如果切割后的剩余部分<MINSIZE,就不会进行切割。
最后会去large bin找,ptmalloc会首先遍历fast bin中的chunk,将相邻的chunk合并(unlink),然后放到unsorted bin中。(这样是为了large bin的最小满足,因为如果你有一个0x20的fast bin和一个0x500的large bin物理相邻,此时申请一个0x510的large bin,如果不合并fast bin,就需要切割top_chunk,这是很大的一块内存),如果在unsorted bin中找到了合适的chunk,就会把chunk分割后返回或者直接返回,如果没找到,就会把合并后的chunk根据大小放到small bin或者large bin中去。
如果还是找不到,就会切割top_chunk,如果连top_chunk都不能满足,就会调用sbrk(),增加top_chunk的大小。
如果申请的内存超过了0x200000B,那么就不会在heap段上分配内存,将会使用mmap在libc的data段分配内存。有一个利用方法就是如果分配的size没有限制,就可以malloc一个很大的内存泄漏libc的地址。
0x02 unlink
unlink将链表头处的free chunk从unsorted bin中脱离出来,然后和物理相邻地址的新free chunk进行合并,然后再放入unsorted bin。
当被free的chunk的p位为0,说明前一个chunk为空,于是对前一个chunk进行unlink操作。
1 | /* Take a chunk off a bin list */ |

0x03 堆利用总结
unlink
利用条件:
- 存在一个全局变量数组,这个数组存储malloc之后的地址。
- 开启pie,否则找不到这个数组就用不了。
- 需要uaf或者off by one修改chunk的PREV_INUSE位,可以修改smallbin 或是 unsorted bin的fd和bk指针时。
- 需要能创建unsorted bin。
利用思路:
1 | add(0x30,"a") |
User After Free
利用条件:
chunk被free后指针没有置0,我们对这块内存进行修改后,程序再次使用这块内存时就会出现问题。
利用思路:
配合其他堆利用使用
off by one
利用条件:
可以溢出一个字节
利用思路:
溢出的那个字节正好为size位,可以修改后free制作堆重叠,寻找指针修改地址。
或者直接unsorted bin attack+fast bin attack。
要注意合并的时候会有验证
off by null
利用条件:
溢出的字节为\x00,这个null字节。在size为0x100的倍数的时候,可以覆盖掉prev_inuse位。
其余和off by one一样。
fast bin double free
在2次free之间free一个其他的fastbin chunk就可以绕过检测。
fast bin attack
利用条件:
可以修改fastbin的fd指针
利用思路:
1 | fake_chunk = malloc_hook - 0x23 |
house of spirit
该技术的核心在于在目标位置处伪造 fastbin chunk,并将其释放,从而达到分配指定地址的 chunk 的目的。
利用条件:
- 可以修改fastbin的fd指针
利用思路:
- 把fastbin链表伪造到malloc_chunk附近,然后修改malloc_chunk的地址
- 要注意fake chunk是0x70,所以我们fake chunk的前一个chunk也要是0x70
1 | fake_chunk = malloc_hook - 0x23 |
unsorted bin attack
利用条件:
- 存在堆溢出,uaf等能控制unsortedbin的指针。
- 存在show函数
house of force
利用条件:
- 能够以溢出等方式控制到 top chunk 的 size 域
- 能够自由地控制堆分配尺寸的大小
house of einherjar
利用条件:
- 需要泄漏堆地址
- 提前布置fake_chunk绕过unlink检测。
house of orange
利用条件:
- 题目没有给出free
- 可以修改top_chunk的size
large bin attack
tcache attack
- double free因为没有检查,可以直接连着free,不需要中间隔一个
- tcache对size没有检测(fastbin有),可以随便整
- fastbin怎么打这个就怎么打
0x04 glibc历史
glibc2.23~2.25 (ubuntu 16.04)
glibc2.26
增加了tcache机制。
对unlink的size进行了校验
glibc2.27 (ubuntu 18.04)
对传入tcache的size进行了校验,防止了整数溢出。